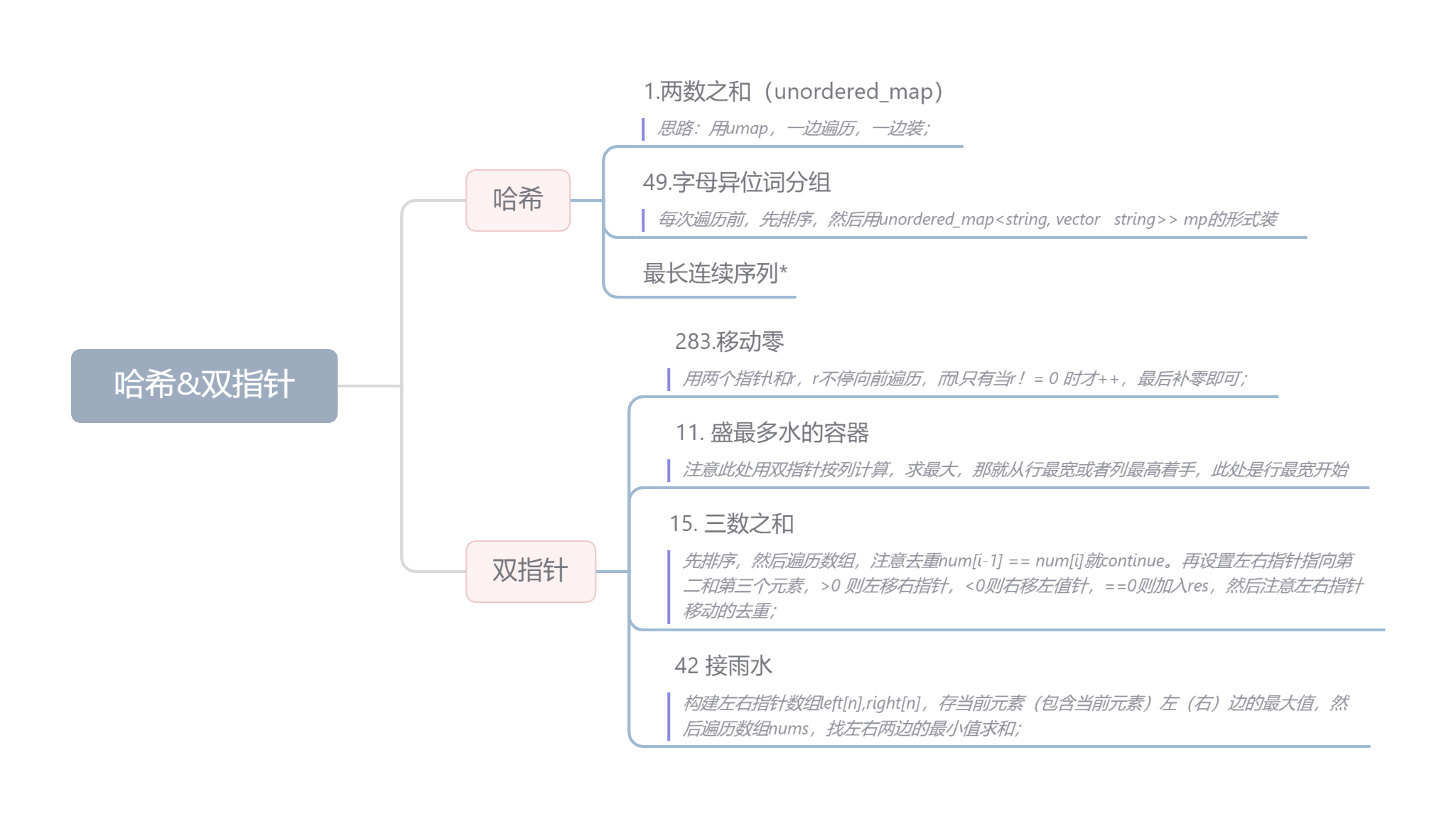
TinyWebsever
00项目来源
qinguoyi/TinyWebServer: :fire: Linux下C++轻量级WebServer服务器 (github.com)
💕学习链接
小白视角:一文读懂社长的TinyWebServer | HU (huixxi.github.io)
(一)TinyWebServer的环境配置与运行-CSDN博客
01 环境配置
👨🎓创建VM虚拟机环境
👨🎓安装数据库
🌷在终端输入以下内容
# 安装mysql |
🌷创建表
# 进入mysql |
create user 'starry'@'%' identified by 'root'; |
create user 'starry'@'%':这部分代码用于创建一个新的MySQL用户,用户名是starry。'%':表示这个用户可以从任何主机连接到MySQL服务器。这个通配符表示所有IP地址。identified by 'root':设置用户starry的密码为root。请注意,使用强密码而不是简单密码(如root)是更安全的做法。
grant all on *.* to 'starry'@'%'; |
grant all:授予所有权限,包括SELECT、INSERT、UPDATE、DELETE、CREATE、DROP等。
on *.*:表示权限适用于所有数据库和所有表。第一个*表示所有数据库,第二个*表示所有表。
to 'starry'@'%':将这些权限赋予用户starry,该用户可以从任何主机连接。
这段代码的效果是:创建一个名为starry的新用户,密码为root,并且允许该用户从任何IP地址连接到MySQL服务器,并对所有数据库的所有表拥有所有权限。
科学上网
参考链接:VMware虚拟机共享主机v2rayN_vmware v2-CSDN博客
🌼解释
网络地址转换
1)NAT 即 网络地址转换,可以将私有网络的 IP 地址映射到公有网络的 IP 地址上,以实现多个设备共享同一个公共 IP 地址来访问互联网。
2)而 VMware 共享本地代理这个过程,就用到了 NAT
3)首先,VMware-Ubuntu是一个虚拟机,在私有网络运行。主机通过 NAT 将虚拟机的 IP 地址映射到自己的公共 IP 上,再通过 V2rayN 访问其他网站
4)当 Ubuntu 通过虚拟网络发出请求时,它的请求会被 NAT 转换成主机的公共 IP,并通过主机的 V2rayN 转发到互联网上。
5)这样,Ubuntu 就能借助主机的代理访问其他网站,而外部网络只能看到主机的 IP,并不知道具体是哪个虚拟机在通信。
🌷检查Mysql状态
systemctl status mysql.service |
🌷查看表和表的内容
sudo mysql -uroot -p //进入mysql环境 |
🌷下载代码,编译运行
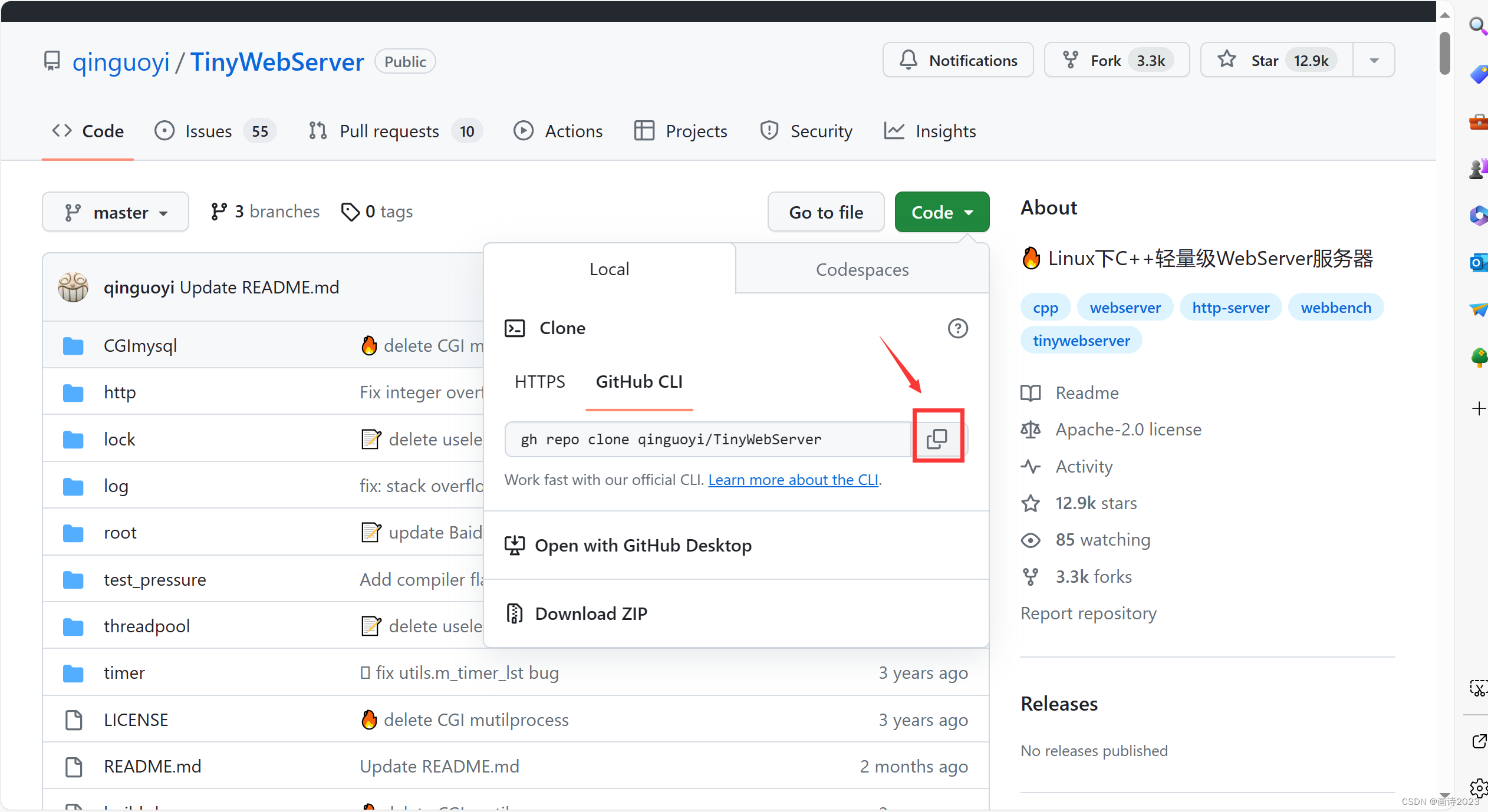
使用git克隆到本地
# 没有git的使用下面命令(有git忽略此步骤) |
首先需要确认main.cpp里的数据库和你mysql数据库配置相同。
查看数据库名称和密码
cd /etc/mysql
sudo vim debian.cnf
# Automatically generated for Debian scripts. DO NOT TOUCH!
[client]
host = localhost
user = debian-sys-maint
password = pKMhSd1835J5AbJD
socket = /var/run/mysqld/mysqld.sock
[mysql_upgrade]
host = localhost
user = debian-sys-maint
password = pKMhSd1835J5AbJD
socket = /var/run/mysqld/mysqld.sock
~
进入项目,修改main.cpp文件配置,执行make
cd TinyWebServer |
编译Tinywebserver(编译运行)
cd Tinywebserver |
运行可执行文件,访问项目
# 运行 |
打开VMware中的浏览器,输入网址后访问
显示登陆界面即可完成登录;
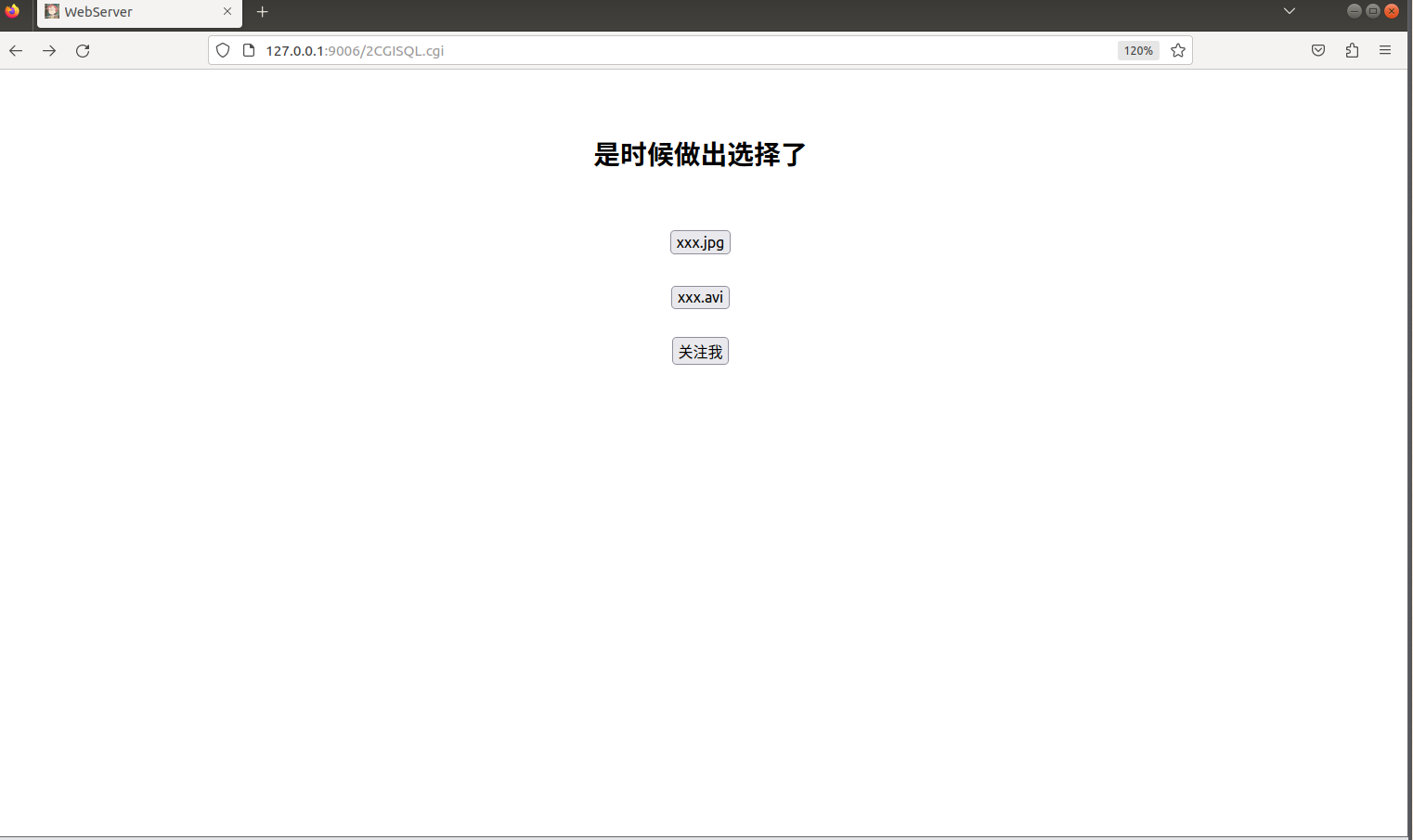
压力测试
1.1安装依赖
sudo apt-get install exuberant-ctags |
1.2下载源码并安装
wget http://blog.s135.com/soft/linux/webbench/webbench-1.5.tar.gz |
参数
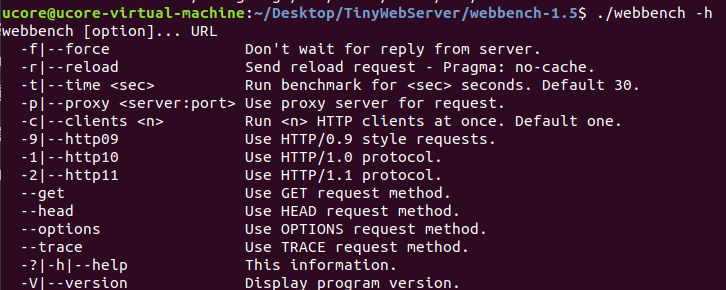
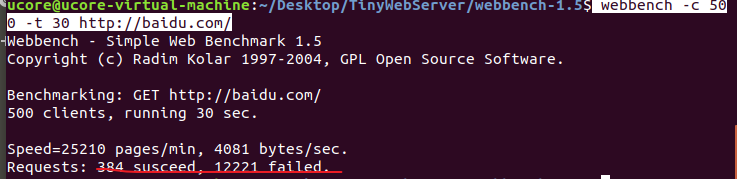
测试百度
webbench -c 500 -t 30 http://baidu.com/ |
测试TinyWebServer
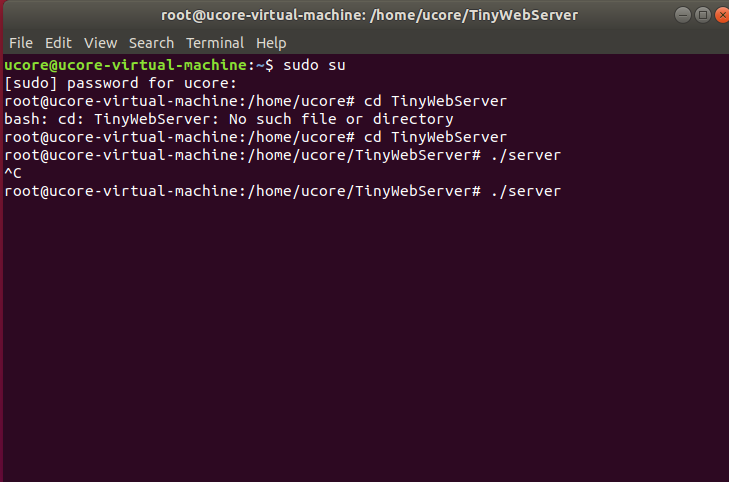
打开新的终端,输入
sudo su |
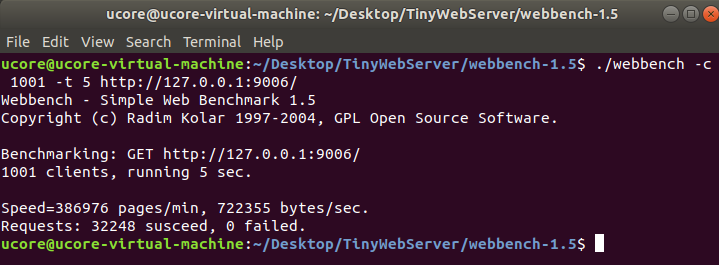
再开1个,webbench测压
./webbench -c 1001 -t 5 http://127.0.0.1:9006/ |
🌷视频无法播放问题
解决方法:
参考链接Ubuntu 播放在线视频显示“没有找到支持的视频格式和 MIME 类型”的解决方案_ubuntu需要额外的mime类型-CSDN博客
1.1环境
软件环境:
这个命令可以显示详细的 Ubuntu 版本信息:
lsb_release -a |
No LSB modules are available. |
在终端中输入以下命令查看 Firefox 的版本:
firefox --version |
Mozilla Firefox 113.0.2
1.2 安装解码器
终端输入 sudo apt install ubuntu-restricted-extras 即可
中断解决方案
修复 dpkg 配置
sudo dpkg –configure -a
修复损坏的软件包
如果有任何损坏的软件包,可以使用以下命令来尝试修复:
-f参数会自动尝试修复损坏的依赖关系,并完成未完成的安装。3. 手动删除问题包
如果问题依然存在,可以尝试手动删除有问题的软件包,然后重新安装:
删除后重新安装:
sudo apt-get install ttf-mscorefonts-installer4. 重新执行安装命令
在解决问题后,重新尝试安装命令:
sudo apt-get install ubuntu-restricted-extras5. 检查网络连接
ttf-mscorefonts-installer是一个需要从外部源下载字体的包,因此,安装过程中可能因为网络问题导致安装失败。请确保你的网络连接正常,并尝试再次安装。6. 查看安装日志
如果仍然遇到问题,可以查看详细的安装日志,了解具体的错误原因:
这将帮助你了解
dpkg返回错误代码 1 的具体原因,从而采取进一步的措施。判断软件包是否成功安装
可以使用
apt或dpkg来查看已安装软件包的详细信息,包括版本号:
例如:
1.3 安装Firefox的flash插件
参考:Linux / Ubuntu在命令行下载安装Flash插件(无需官网下载tar包)_apt search flash plugin-CSDN博客
…flash官网不支持下载了,捯饬了好久,在博主这找到了答案
sudo apt install flashplugin-installer
sudo apt install browser-plugin-freshplayer-pepperflash
中间可能需要sudo-get update一下
sudo-get update
完美解决问题:

没有声音的问题:
Ubuntu系统 –火狐浏览器– 安装 flash播放器–百度翻译发不出声音_火狐百度汉语没声音-CSDN博客
2024-08-09 用google验证了一下好像是视频的问题
👨🎓尝试配置Linux环境下的VScode
参考链接linux下使用vscode搭建C++开发环境_linux vscode写c++-CSDN博客
VS Code的C/C++环境配置的傻瓜式教程(看这一篇就够了) - 咩sir - 博客园 (cnblogs.com)&GPT
linux系统下g++,gdb自带,关键在于配置tasks.json,launch.json和c_cpp_properties.json
tasks.json
"version": "2.0.0",
"tasks": [
{
"type": "cppbuild",
"label": "C/C++: g++ build active file",
"command": "/usr/bin/g++",
"args": [
"-fdiagnostics-color=always",
"-g",
//如果你的 main 函数文件和其他 .cpp 文件在不同的目录下,你需要在 tasks.json 中正确地指定这些文件 的位置。
"${workspaceFolder}/*.cpp", //包含了主函数文件
"${workspaceFolder}/**/*.cpp", //包含了子文件夹中的所有 .cpp 文件。
"-lpthread",
"-lmysqlclient",
"-o",
"${workspaceFolder}/${workspaceRootFolderName}.out"
],
"options": {
"cwd": "${workspaceFolder}"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
},
"detail": "compiler: /usr/bin/g++"
}
]
>}launch.json
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "C/C++: g++ build and debug active file",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/${workspaceRootFolderName}.out",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"miDebuggerPath": "/usr/bin/gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
"preLaunchTask": "C/C++: g++ build active file"
}
]
>}c_cpp_properties.json
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/**"
],
"defines": [],
"compilerPath": "/usr/bin/gcc",
"cStandard": "c11",
"cppStandard": "gnu++14",
"intelliSenseMode": "linux-gcc-x64"
}
],
"version": 4
>}
02 前置知识补充
推荐B站up:码农的荒岛求生
🌷本地访问和外地访问
🌻本地访问 (Local Access)
“本地访问”指的是你在同一台计算机或设备上访问由该计算机或设备运行的服务。例如,如果你在自己的电脑上运行了一个Web服务器(比如通过某个编程语言启动的服务器程序),你可以使用本地访问来连接到它。
- **回环地址 (Loopback Address)**:
127.0.0.1是一个特殊的IP地址,用于指代本地计算机。使用这个地址可以让计算机自己与自己通信。例如,当你在浏览器中输入127.0.0.1:9000或localhost:9000,你实际上是在请求访问本地计算机上的端口9000的服务。 - **端口 (Port)**:端口是网络上的一个虚拟接口,用来区分不同的网络服务。每个服务通常绑定到一个特定的端口,例如Web服务器通常运行在端口80(HTTP)或443(HTTPS),但你可以选择其他端口号来运行你自己的服务器。
🌻外地访问 (Remote Access)
“外地访问”指的是通过网络从另一台计算机或设备访问Web服务器或服务。这通常涉及通过一个公开的IP地址或者域名来访问运行在远程服务器上的服务。
- **公网IP地址 (Public IP Address)**:如果Web服务器绑定在一个公网IP地址上,那么其他计算机可以通过这个IP地址进行访问。
- **域名 (Domain Name)**:通常,公网IP地址会绑定到一个域名上,这样用户可以通过易记的域名来访问服务,而不需要记住复杂的IP地址。
🌻举例说明
- 本地访问:假设你在自己的电脑上启动了一个Web服务器,绑定在
127.0.0.1和端口9000上。此时,你可以在浏览器中输入127.0.0.1:9000或localhost:9000来访问这个服务器。只有你自己这台电脑能访问这个服务。 - 外地访问:假设你将同样的Web服务器绑定在一个公网IP地址上(比如
203.0.113.1),并开放了端口9000。其他人可以在他们的浏览器中输入203.0.113.1:9000来访问这个Web服务器。
🌷同步、异步
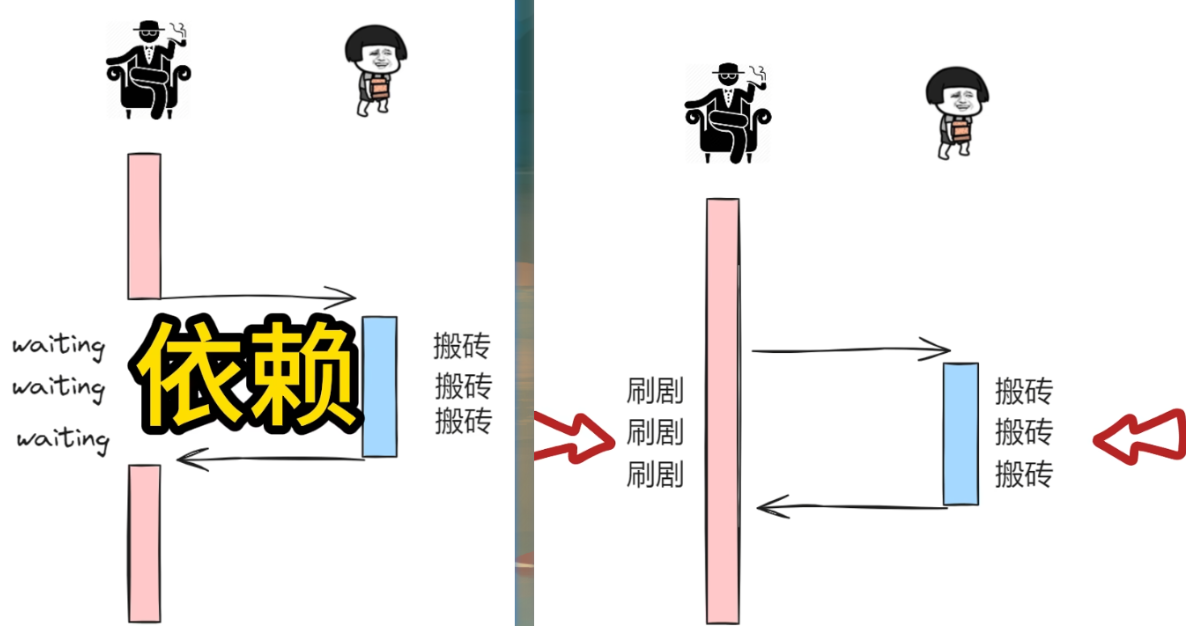
举个例子:
现在老板有一项紧急任务交给你去处理,在这个过程中他要盯着你等待你完成任务才能做自己的事情,因此你和他之间就形成了一种依赖,这就是同步(左图);隔天老板又给你安排了一项任务,但这次他没有盯着你而是忙自己的事情去了,你和他之间不存在依赖关系,这就是异步(右图);
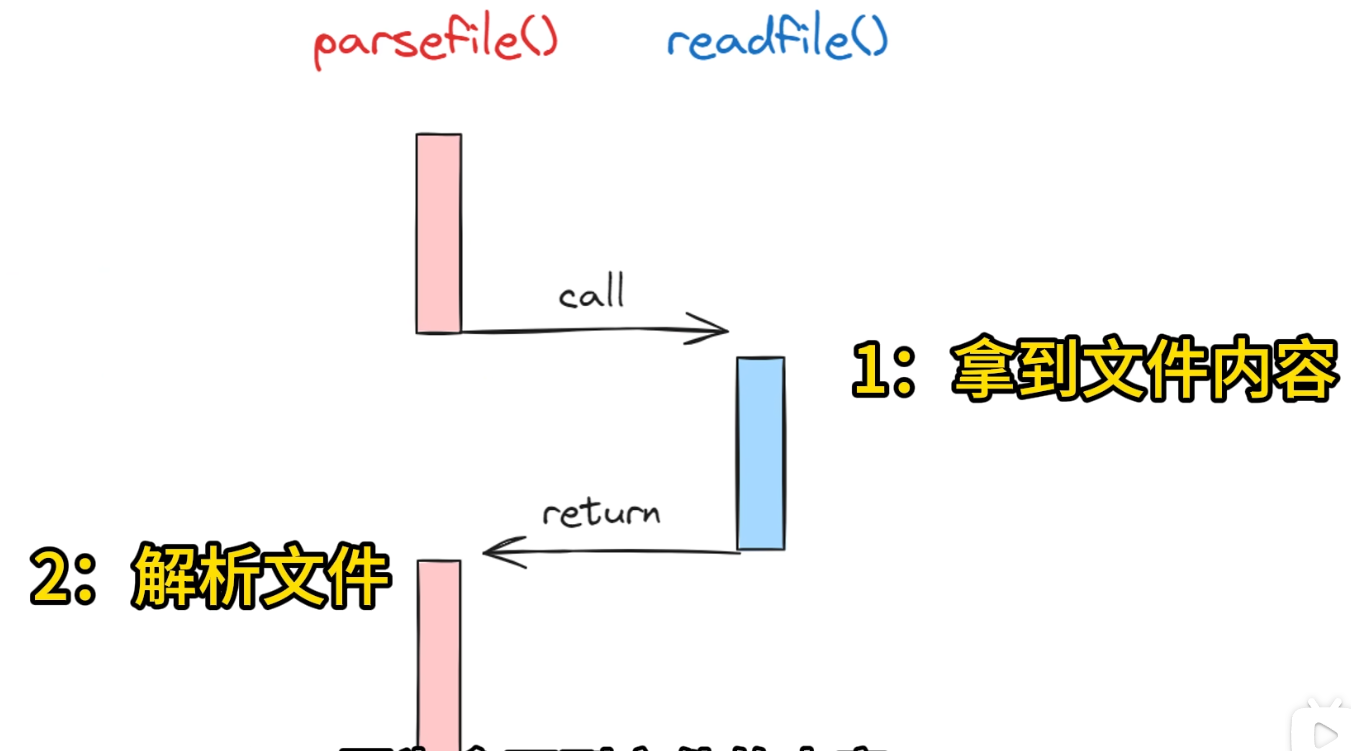
回到编程
void parsefile(){ //作用是读取a.txt的内容,然后调用parse解析文件 |
void parsefile(){ //作用是读取a.txt的内容,同时处理用户输入 |
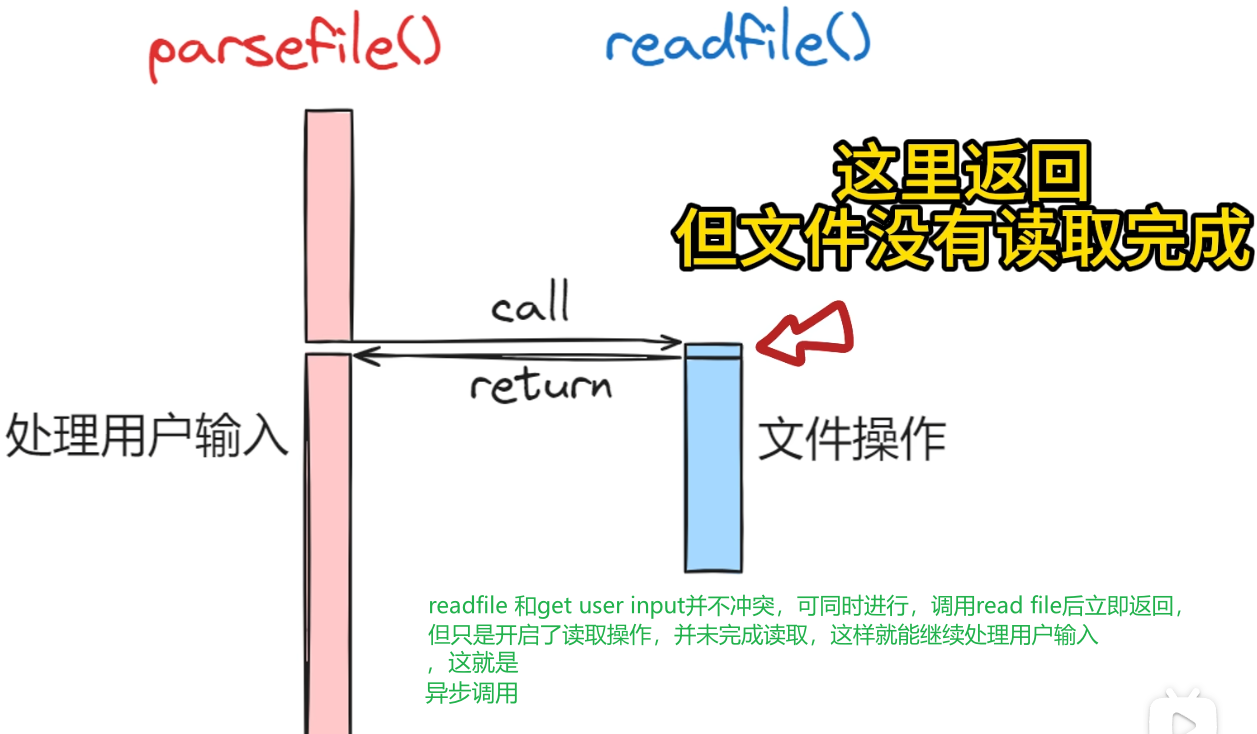

同步 (Synchronous)
使用场景:
- 顺序执行: 当一个任务必须在另一个任务完成后才能继续时,使用同步。
- 简单逻辑: 当业务逻辑较为简单,不需要处理复杂的回调或者并发时,使用同步代码通常更直观、更易于理解。
- 低并发需求: 当系统的并发需求较低,且不需要处理大量的请求时,同步执行可能更为适合。
- 资源受限: 当系统资源(如CPU、内存)有限时,使用同步可以避免不必要的线程切换和资源消耗。
差异:
- 同步方法会阻塞调用线程,直到任务完成后才继续执行下一个任务。
- 编码和调试较为简单,因为程序执行流程是线性的。
- 适合小规模任务或需要顺序执行的任务。
异步 (Asynchronous)
使用场景:
- 高并发需求: 当系统需要处理大量并发请求时,异步可以提高系统的吞吐量和响应速度。
- 长时间任务: 当某些任务可能耗时较长(如I/O操作、网络请求)时,异步可以避免阻塞主线程,从而提升系统的响应能力。
- 用户界面: 在前端开发中,异步操作可以避免阻塞UI线程,从而提升用户体验。
- 资源密集型任务: 当某些任务需要消耗大量的资源时,异步可以将这些任务放在后台执行,从而不影响主任务的执行。
差异:
- 异步方法不会阻塞调用线程,任务通常会被放入事件队列中,等到结果返回时再处理回调或Promise。
- 编码和调试可能更复杂,因为涉及回调、Promise或async/await等机制。
- 适合处理大规模并发任务或需要响应速度的场景。
RPC接口(Remote Procedure Call)
RPC接口本质上可以是同步的也可以是异步的,取决于实现和需求:
- 同步RPC: 调用方会阻塞,直到远程过程执行完毕并返回结果。这种方式简单易懂,适用于需要依赖远程服务返回结果才能继续的场景。
- 异步RPC: 调用方发出请求后不会等待结果,而是继续执行其他任务,结果会在回调中处理。适用于高并发、需要提升系统响应速度的场景。
总结
- 同步适合任务需要顺序执行或系统并发需求较低的场景。
- 异步适合需要提升并发性能、响应速度,或处理耗时任务的场景。
- RPC接口可以是同步的,也可以是异步的,具体取决于应用的需求。
🌷Socket
Linux是由C语言实现的,c并没有继承的特性,那他是怎么达到继承的效果的呢
1. 结构体嵌套:
在C中,可以通过结构体嵌套来实现类似继承的功能。一个结构体可以包含另一个结构体作为其成员,从而实现类似于“基类”的功能。例如:
typedef struct { |
在这个例子中,DerivedStruct结构体包含了BaseStruct,因此可以通过DerivedStruct来访问BaseStruct中的成员,如x和y。
2. 函数指针:
函数指针可以用来实现类似于多态的效果。在结构体中,可以包含函数指针作为成员,从而在运行时可以调用不同的函数。这在Linux内核的驱动程序中非常常见。例如:
typedef struct { |
3. 接口模拟:
通过定义函数和结构体,可以模拟接口的效果。不同的结构体可以实现相同的函数签名,从而可以在相同的上下文中调用不同的实现。
4. 宏定义:
宏定义可以用来减少代码重复,并且可以通过组合宏实现类似于继承的效果。例如,可以定义一个宏来自动生成某些字段和函数的定义。
5. 组合(Composition):
通过组合多个结构体或者模块,可以实现代码复用,这与面向对象编程中的继承相似。组合强调的是“有一个”(has-a)的关系,而不是“是一个”(is-a)的关系。
以上这些方法使得C程序员可以在不具备面向对象语言特性的情况下,实现类似于继承和多态的效果。在Linux内核中,这种技术被广泛应用,特别是在实现设备驱动程序和文件系统时。
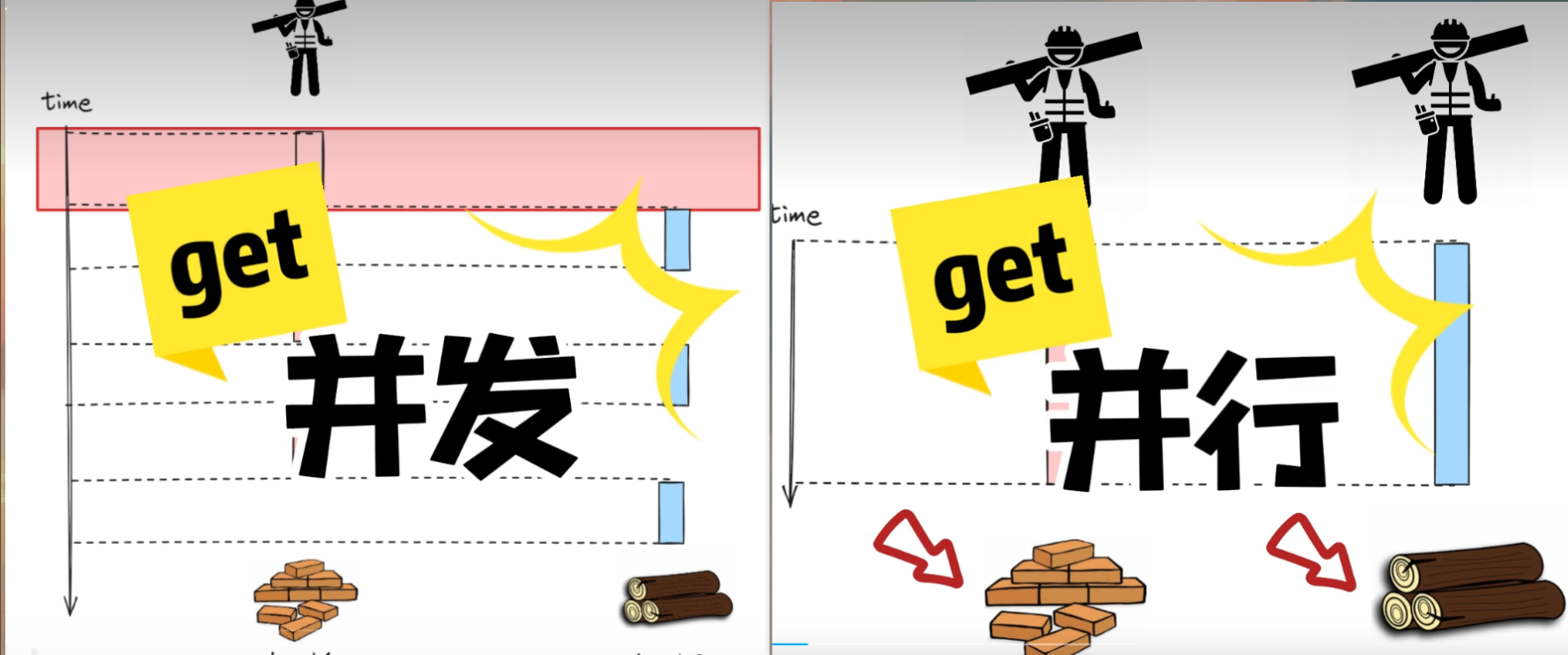
🌷并发和并行
线程就是CPU需要执行的任务
🌷堆区和栈区
堆区:变量的生命周期受程序员控制,超越函数内部
栈区:变量的生命周期局限在函数
由于进程中的所有线程共享一个堆区,因此堆区需要解决线程安全问题
🌷日志系统
less命令
less基础命令
ctrl + f 向后翻页
ctrl + b 向前翻页
g —— 跳到首行
G——跳到尾行,同时按shift+g
/abc——向后搜索abc,再按n继续搜索上一个abc,N搜索下一个abc
?abc——向前搜索abc,再按n继续搜索上一个abc,N搜索下一个abc
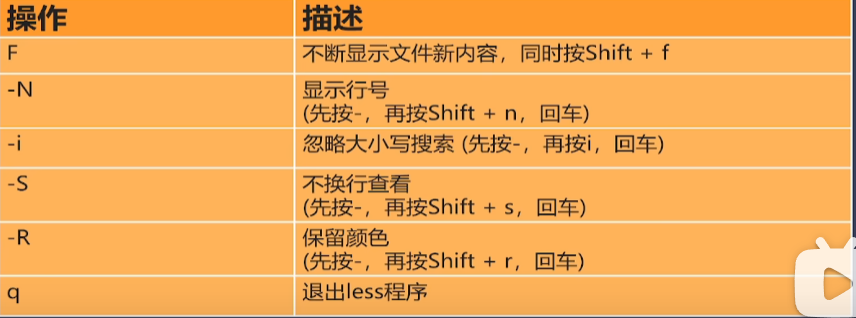
less提供了&功能,可快速过滤掉不想看的日志,Non-match模式
03《Linux 高性能服务器编程》
ernest-laptop(客户端)
Kongming20(服务器)
🌷Tcp/ip协议详解
Linux下访问DNS服务
Linux下访问DNS服务:/etc/resolv.conf文件存放DNS服务器的IP地址
host -t A www.baidu.com |
使用Tcpdump观察DNS通信过程
要打开两个终端
ucore@ucore-virtual-machine:~$ ip link show //查看系统中可用的网络接口名称: |
# 终端1:运行 tcpdump 抓取数据包 |
NAT地址转换
主机字节序 —— 小端字节序
网络字节序 ——大端字节序
IP地址
【硬核科普】IP地址是什么东西?IPV6和IPV4有什么区别?公网IP和私有IP又是什么?_哔哩哔哩_bilibili
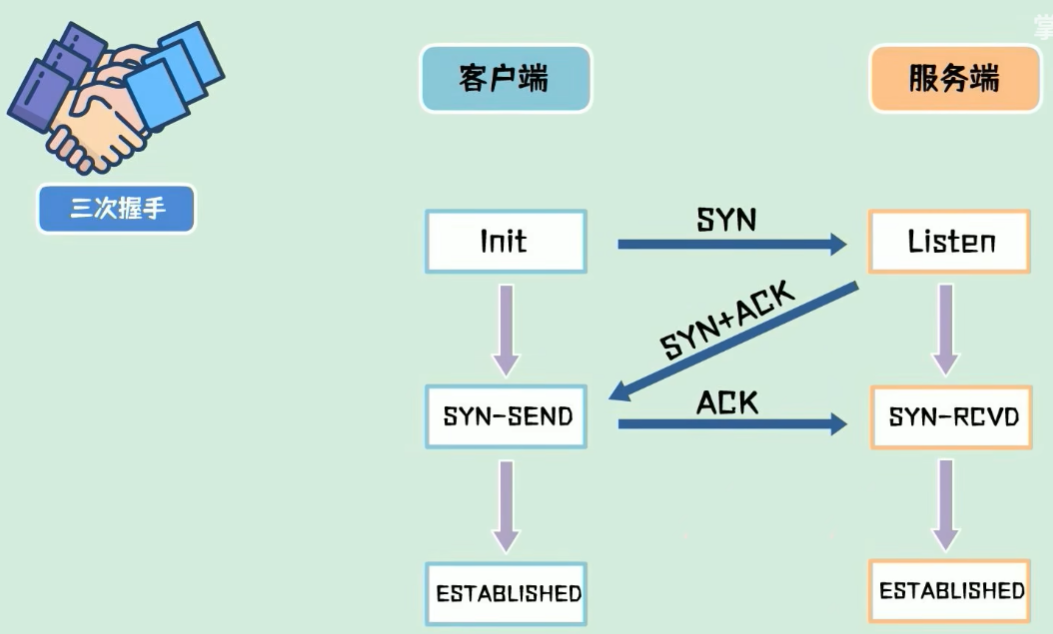
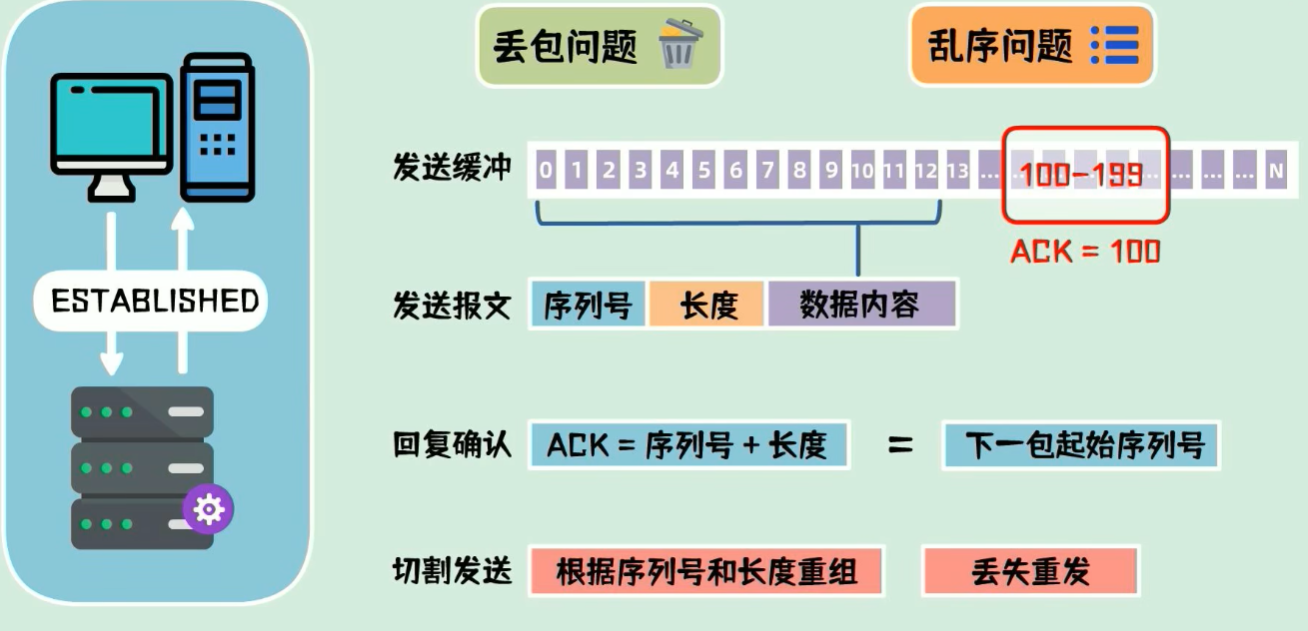
TCP协议
三次握手
四次挥手
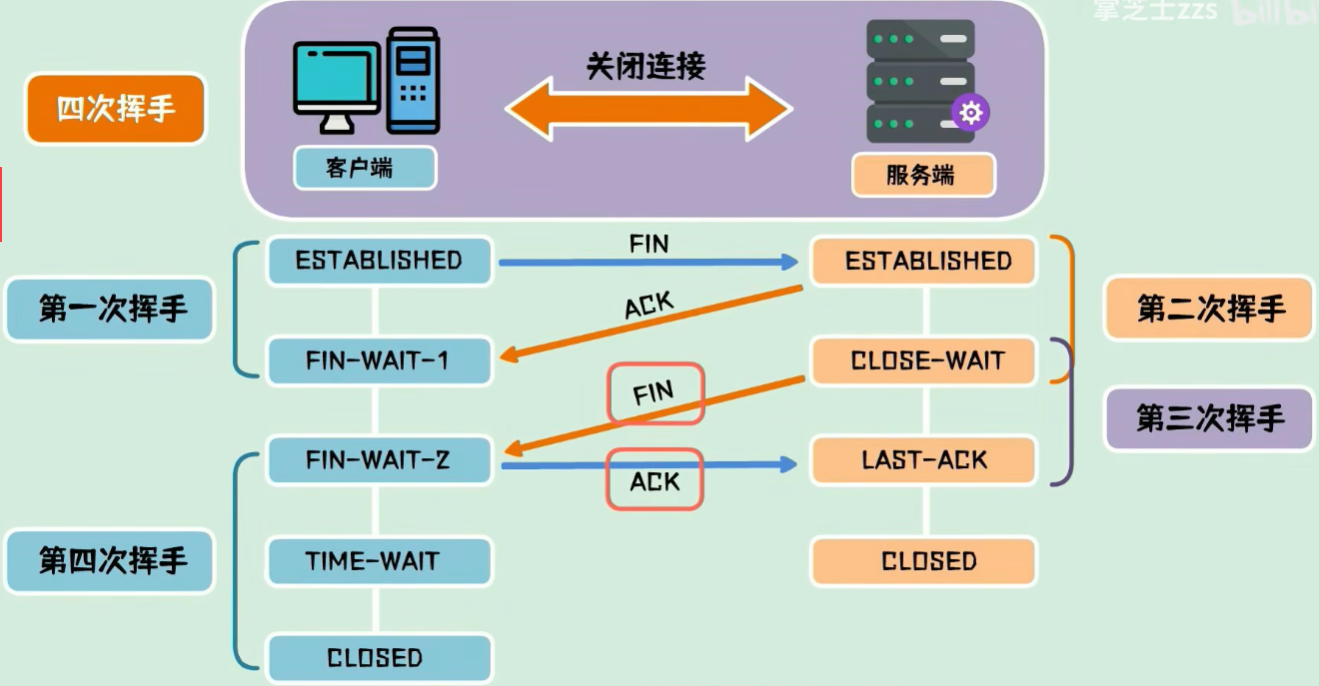
全双工:即双方的数据读写可以通过一个连接进行。完成数据交换后,通信双方都必须断开连接以释放系统资源。
双工(Full Duplex)和半双工(Half Duplex)是指数据通信中的两种不同模式,定义了通信双方在同一时间内能否同时发送和接收数据。
全双工(Full Duplex)
全双工是一种数据通信模式,在这种模式下,通信双方可以同时发送和接收数据。这意味着通信链路的两端可以同时进行数据的传输,而不会相互干扰。全双工模式类似于双向车道,可以同时允许两个方向上的数据流动。
特点:
- 同时通信:发送和接收可以同时进行。
- 高效:全双工通信能够充分利用带宽,提高数据传输效率。
- 应用场景:常用于电话通信、现代计算机网络、无线通信(如 Wi-Fi)、以太网等。比如,当你使用手机打电话时,你和对方可以同时说话和听到对方的声音,这就是全双工通信。
半双工(Half Duplex)
半双工是一种数据通信模式,在这种模式下,通信双方可以在同一时间内只能有一方发送数据,另一方必须等待传输完成后再发送数据。这类似于单向车道,在某一时刻只能有一个方向的车流通行。
特点:
- 交替通信:通信双方不能同时发送数据,只能轮流进行发送和接收。
- 效率低于全双工:由于双方不能同时通信,传输效率相对较低。
- 应用场景:常用于对讲机、老式的网络设备(如早期的以太网集线器)、串行通信等。比如,当你使用对讲机时,你需要按住通话键才能说话,而对方则在你松开通话键后才能回应,这就是半双工通信。
对比总结
- 同时通信:全双工允许同时进行发送和接收,而半双工则不允许。
- 带宽利用:全双工能更有效地利用通信带宽,而半双工在某一时刻只能使用一半的带宽。
- 复杂性:全双工系统通常比半双工系统更复杂,因为它们需要更多的硬件支持来处理双向同时通信。
在现代通信系统中,全双工模式由于其高效性,已经成为主流,特别是在高速网络和无线通信领域。然而,半双工仍然在一些特殊应用中被广泛使用,如对讲机和某些老式网络设备。
字节流服务:TCP
数据报服务:UDP
守护进程
守护进程(Daemon)是计算机系统中的一种特殊进程,它在后台运行,通常不与任何特定的终端或用户会话关联。守护进程的主要用途是执行一些需要持续运行的任务,或者是等待某些事件发生时执行特定的操作。
为什么要有守护进程:
- 持续运行:守护进程可以持续运行,不受用户登录或注销的影响。
- 资源占用:它们通常设计得资源占用较少,不会影响用户正常使用系统。
- 系统服务:许多系统服务,如网络服务、打印服务等,都是通过守护进程来实现的。
- 自动化:守护进程可以自动执行任务,无需用户干预。
守护进程的用途:
- 系统监控:监控系统状态,如CPU使用率、内存使用情况等。
- 网络服务:提供网络服务,如Web服务器、邮件服务器等。
- 定时任务:执行定时任务,如定时备份数据、定时发送邮件等。
- 事件响应:响应系统事件,如打印任务、硬件状态变化等。
- 资源管理:管理系统资源,如磁盘空间、网络带宽等。
守护进程通常以较低的优先级运行,以避免影响用户的主要任务。它们是操作系统中不可或缺的一部分,确保了系统服务的稳定和高效运行。
服务器模型
C/S模型、P2P模型
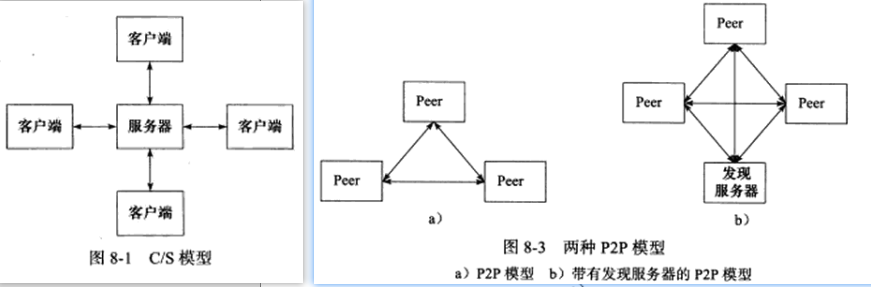
服务器编程框架
基本框架
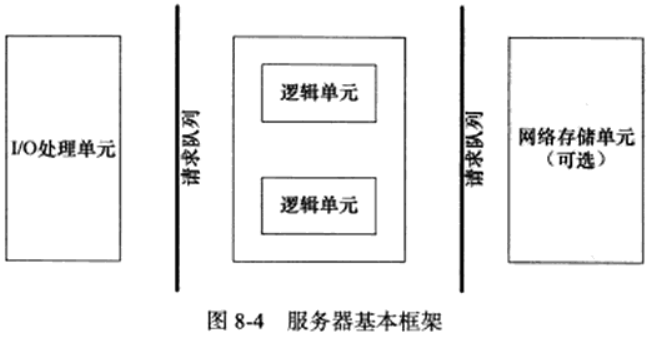
基本模块功能

I/O模型
阻塞的文件描述符称为阻塞IO,非阻塞的文件描述符称为非阻塞IO

非阻塞I/O(Input/Output)确实可以在事件发生之前或之后立即返回,但它的返回并不意味着I/O操作已经完成。非阻塞I/O的关键在于它允许程序在I/O操作尚未完成时继续执行,而不是等待I/O操作完成。这种机制提高了程序的效率,因为它允许程序在等待数据时执行其他任务。
当提到“事件已经发生”时,这通常是指I/O操作(如读取或写入)已经可以进行,即数据已经准备好被读取或写入。在非阻塞I/O中,如果尝试进行I/O操作时数据尚未准备好,操作会立即返回一个错误,通常是EWOULDBLOCK或EAGAIN,表示操作不能立即完成。
以下是非阻塞I/O的一些关键点:
- 立即返回:非阻塞I/O调用会立即返回,即使数据还没有准备好。这与阻塞I/O不同,后者会等待直到数据准备好。
- 轮询:在非阻塞I/O中,程序可能需要轮询I/O操作,即反复检查I/O操作是否可以完成,直到操作成功或出现错误。
- I/O通知机制:为了提高效率,非阻塞I/O通常与I/O通知机制结合使用,如I/O复用(例如使用
select、poll或epoll系统调用)或SIGIO信号。这些机制允许程序知道何时可以进行I/O操作,而不必轮询。 - 效率:非阻塞I/O可以提高程序的效率,因为它允许程序在等待I/O操作完成时执行其他任务,从而更好地利用系统资源。
- 适用场景:非阻塞I/O适用于需要高性能和高并发的应用程序,如网络服务器、数据库系统等。
- 编程复杂性:使用非阻塞I/O可能会增加编程的复杂性,因为需要处理I/O操作的异步性质和可能的错误情况。
- 事件驱动:在事件驱动的编程模型中,非阻塞I/O与事件循环结合使用,可以有效地处理多个I/O源。
- 异步I/O:非阻塞I/O是实现异步I/O的基础,异步I/O允许程序在等待I/O操作完成时不被阻塞,并且可以在操作完成时接收通知。
总之,非阻塞I/O的设计目的是提高程序的响应性和效率,但它需要与适当的I/O通知机制结合使用,以避免不必要的轮询和提高程序的整体性能。
同步IO和异步IO
同步I/O(Input/Output)和异步I/O是两种不同的I/O操作模式,它们在处理数据输入输出时的行为和性能特点有所不同。以下是它们的主要区别:
- 操作模式:
- 同步I/O:在同步I/O中,调用I/O操作后,调用者(通常是程序)必须等待I/O操作完成才能继续执行。这意味着在I/O操作进行时,调用者被阻塞,不能执行其他任务。
- 异步I/O:在异步I/O中,调用者发起I/O请求后,不会被阻塞,可以继续执行其他任务。当I/O操作完成时,调用者会收到通知(可能是回调函数、信号、状态变化等),然后可以处理结果。
- 性能:
- 同步I/O通常适用于I/O操作较少或I/O操作较快的情况,因为它的实现相对简单。
- 异步I/O可以提高性能,特别是在高并发或I/O操作较慢的情况下,因为它允许程序在等待I/O操作完成时执行其他任务。
- 编程复杂性:
- 同步I/O的编程模型相对简单,因为它遵循请求-等待-响应的直接模式。
- 异步I/O的编程模型更复杂,需要处理回调、事件循环、状态管理等,这可能导致代码难以理解和维护。
- 资源使用:
- 同步I/O可能导致资源浪费,因为调用者在等待I/O操作时不能做其他事情。
- 异步I/O可以更有效地使用资源,因为调用者可以在等待I/O操作时执行其他任务。
- 适用场景:
- 同步I/O适用于I/O操作较少或对实时性要求不高的场景。
- 异步I/O适用于需要处理大量并发I/O请求或对实时性要求较高的场景,如网络服务器、数据库操作等。
- 错误处理:
- 在同步I/O中,错误通常在I/O操作完成后立即返回。
- 在异步I/O中,错误处理可能更复杂,需要在接收到I/O完成通知时检查错误状态。
- 控制流:
- 同步I/O的控制流是线性的,按照代码的顺序执行。
- 异步I/O的控制流可能是非线性的,因为I/O操作的完成和处理可能在代码的不同部分。
- 多线程和多进程:
- 同步I/O可以通过多线程或多进程来实现并发,但这可能会增加资源消耗和管理复杂性。
- 异步I/O通常与事件驱动模型结合使用,可以在单个线程中处理多个I/O请求,减少资源消耗。
Reactor和Proactor事件处理模式
9.3 高性能网络模式:Reactor 和 Proactor | 小林coding (xiaolincoding.com)
Reactor
您提出了一个非常关键的问题。确实,如果一个线程阻塞在系统调用上,那么在等待期间它不能处理其他连接,这在表面上看起来似乎会降低效率。然而,Reactor模式通过使用事件多路复用技术(如select、poll或epoll)来有效地解决这个问题。下面是如何提高效率的几个关键点:
事件多路复用:Reactor模式使用事件多路复用器(如epoll)来同时监控多个连接的状态。这些系统调用允许线程同时查询多个连接,而不是逐个检查每个连接。
非阻塞I/O:在Reactor模式中,I/O操作通常是非阻塞的。这意味着线程不会在单个I/O操作上无限期地等待,而是可以快速地检查多个连接。
内核帮助检测:通过将关心的连接列表传递给内核,内核可以在后台检测这些连接的状态,而不需要应用程序线程不断地轮询每个连接。
高效唤醒:当内核检测到某个连接上有事件发生时(如数据到达),它会立即通知应用程序线程。线程从阻塞状态返回,然后可以立即处理该事件。
线程池:Reactor模式通常与线程池结合使用。这样,即使主线程被阻塞在系统调用上,其他线程也可以继续处理其他连接的事件。
事件驱动:Reactor模式是事件驱动的,这意味着线程只有在有事件发生时才需要处理连接,而不是不断地轮询每个连接。
减少上下文切换:由于线程不需要不断地在多个连接之间切换,因此可以减少上下文切换的开销。
可扩展性:Reactor模式可以很好地扩展到处理成千上万个连接,因为它依赖于高效的内核级事件通知机制。
总的来说,虽然单个线程在等待系统调用时可能看起来是阻塞的,但Reactor模式通过事件多路复用和内核的帮助,确保了线程可以在事件发生时迅速响应,从而提高了整体的处理效率和可扩展性。
Reactor模式与线程池结合使用的概念可能有些混淆,让我来澄清一下。
在Reactor模式中,通常有一个或多个主线程(有时称为Reactor线程)负责监听和分发事件。这些主线程使用事件多路复用技术(如select、poll或epoll)来监控多个I/O连接的状态。当某个连接上有事件发生时,主线程会将这个事件分发给相应的处理器进行处理。
这里的关键点是,主线程并不直接处理所有的I/O操作,而是负责将事件分发给其他线程或处理器。这就是线程池可以发挥作用的地方:
事件分发:当主线程检测到某个连接上的事件发生时,它可以将这个事件的处理任务分发给线程池中的一个工作线程。
线程池的工作:线程池中的工作线程负责实际的I/O操作,如读取数据、处理数据或写入数据。这些工作线程可以并行工作,同时处理多个连接的事件。
非阻塞调用:主线程在调用
epoll_wait()或其他事件多路复用函数时,通常是非阻塞的。这意味着如果当前没有事件发生,主线程不会无限期地等待,而是可以继续检查其他连接的状态。提高效率:通过这种方式,即使主线程在等待事件时被阻塞,线程池中的其他线程也可以继续处理其他已经分发的事件,从而提高了整体的处理效率。
资源利用:线程池允许应用程序更有效地利用系统资源,因为它可以根据需要动态地调整线程的数量,以适应当前的工作负载。
错误处理:如果某个工作线程因为某个连接上的错误而阻塞,这不会影响其他线程继续处理其他连接的事件。
可扩展性:线程池和Reactor模式的结合使得系统能够处理大量的并发连接,因为它们可以扩展以适应增加的工作负载。
总之,Reactor模式与线程池的结合使用,允许系统在主线程等待I/O事件的同时,利用线程池中的其他线程来并行处理这些事件,从而提高了应用程序的并发处理能力和整体效率。
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景
Redis 是田C语言实现的,在 Redis 6.0 版本之前采用的正是单 Reactor 单进程的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶领不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
Proactor
阻塞IO和非阻塞IO,同步异步下面链接也有解释
9.3 高性能网络模式:Reactor 和 Proactor | 小林coding (xiaolincoding.com)
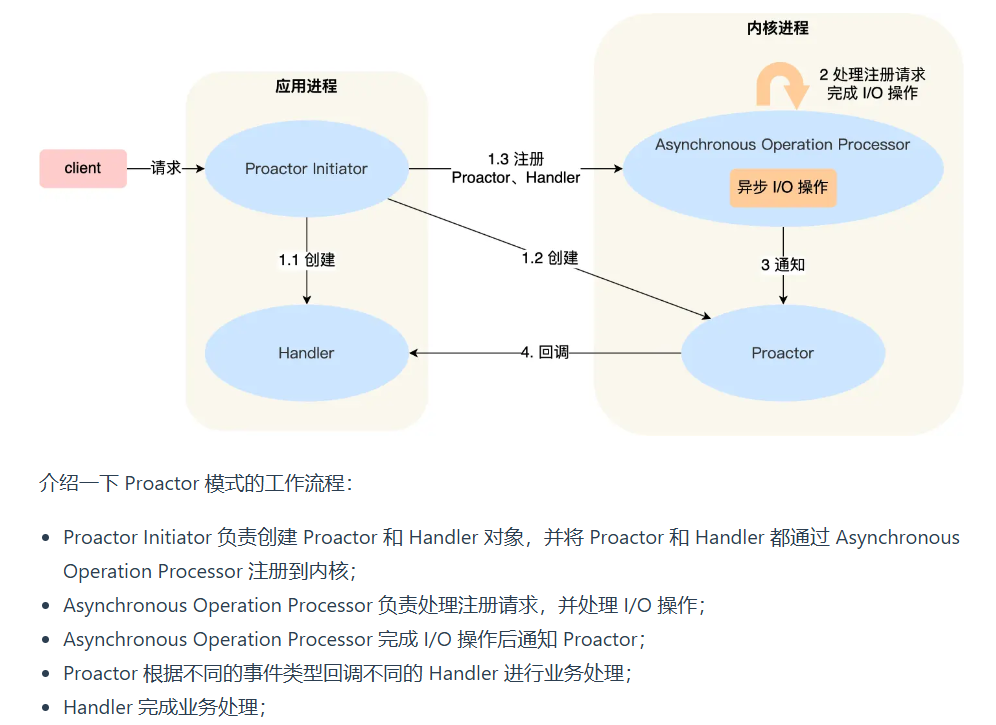

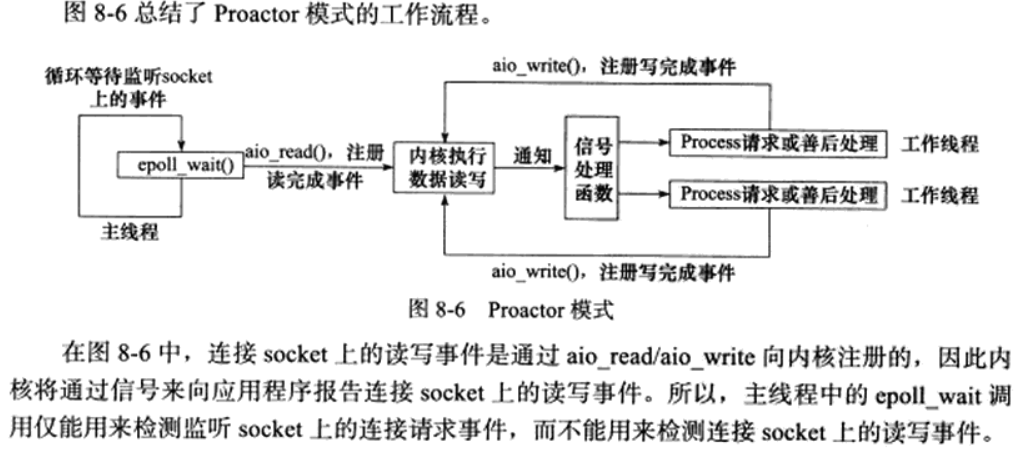
为什么说只能检测监听socket上的连接请求事件,而不能用来检测其他读事件
在Proactor模式中,主线程通常负责监听服务器的监听socket(listening socket),等待新的客户端连接请求。而实际的读写操作是由内核异步完成的,并通过信号或回调函数来通知应用程序。下面是为什么epoll_wait()只能用来检测监听socket上的连接请求事件,而不能用来检测其他连接socket上的读写事件的原因:
异步I/O操作:在Proactor模式中,读写操作是异步进行的。这意味着应用程序通过
aio_read()或aio_write()向内核注册读写请求,然后内核会在后台执行这些操作。信号或回调通知:当异步读写操作完成时,内核会通过信号或回调函数来通知应用程序。这样,应用程序不需要轮询或阻塞等待I/O操作的完成。
epoll_wait()的局限性:
epoll_wait()是一个同步的I/O多路复用系统调用,它用于检测多个文件描述符(如socket)的状态。然而,它主要用于检测同步I/O操作的状态,而不是异步I/O操作。监听socket的特殊性:监听socket的目的是接受新的客户端连接请求。当一个新的客户端连接建立时,监听socket的状态会发生变化,这时
epoll_wait()可以检测到这种变化并通知主线程。连接socket的读写事件:对于已经建立连接的socket,其读写事件是通过异步I/O操作注册的。由于这些操作是异步的,它们不需要通过
epoll_wait()来检测,而是通过内核的信号或回调机制来通知应用程序。工作线程的角色:在Proactor模式中,工作线程通常负责处理异步读写操作完成后的后续工作,如数据处理或错误处理。这些工作线程不需要依赖
epoll_wait()来获取事件通知。提高效率:通过将同步和异步事件的处理分开,Proactor模式可以更高效地利用系统资源,避免不必要的阻塞和轮询。
总之,epoll_wait()主要用于检测同步I/O操作的状态,如监听socket上的连接请求事件。而对于通过异步I/O操作注册的读写事件,它们是通过内核的信号或回调机制来通知应用程序的,因此不需要使用epoll_wait()来检测。这种分离确保了Proactor模式的高效性和灵活性。
就绪的文件描述符通常指的是操作系统中,文件描述符(file descriptor)已经准备好进行I/O操作的状态。
两种高效的并发模式
并发模式是指IO处理单元和多个逻辑单元之间协调完成任务的方法。服务器有两种并发编程模式:
半同步半异步模式和领导者追随者模式;
与IO模型中的同步异步不同,在并发模式中,同步指的是程序完全按照代码序列的顺序执行;异步指的是程序的执行需要由系统事件来驱动。常见的系统事件包括中断、信号等;
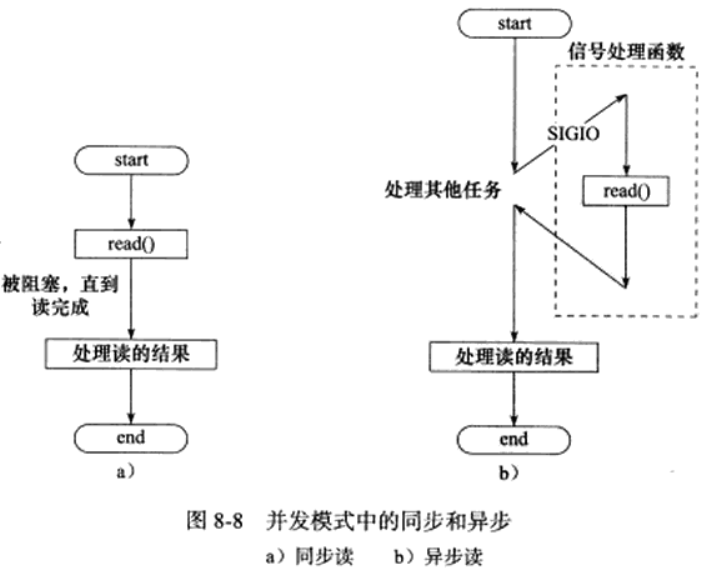
半同步半异步模式中,同步用于处理客户逻辑,异步用于处理IO事件;
LT模式和ET模式
epoll对文件描述符的操作有两种模式:LT电平触发模式和ET边沿触发模式。
对于采用LT工作模式的文件描述符,当epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。这样,当应用程序下一次调用epoll_wait时,epoll_wait还会再次向应用程序通告此事件,直到该事件被处理。而对于采用ET工作模式的文件描述符,当epollwait检测到其上有事件发生并将此事件通知应用程序后,应用程序必须立即处理该事件,因为后续的epollwait调用将不再向应用程序通知这一事件。可见,ET模式在很大程度上降低了同一个epoll事件被重复触发的次数,因此效率要比LT模式高。
IO复用select/poll/epoll
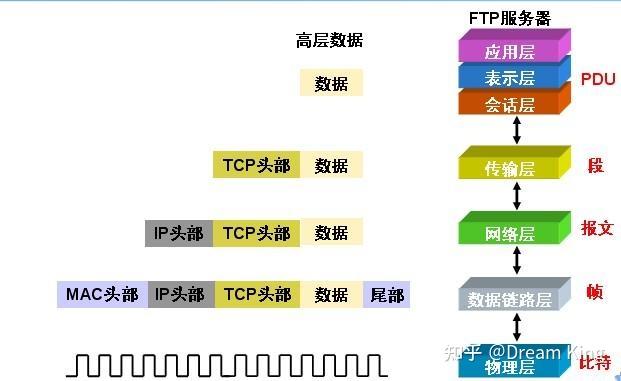
9.2 I/O 多路复用:select/poll/epoll | 小林coding (xiaolincoding.com)
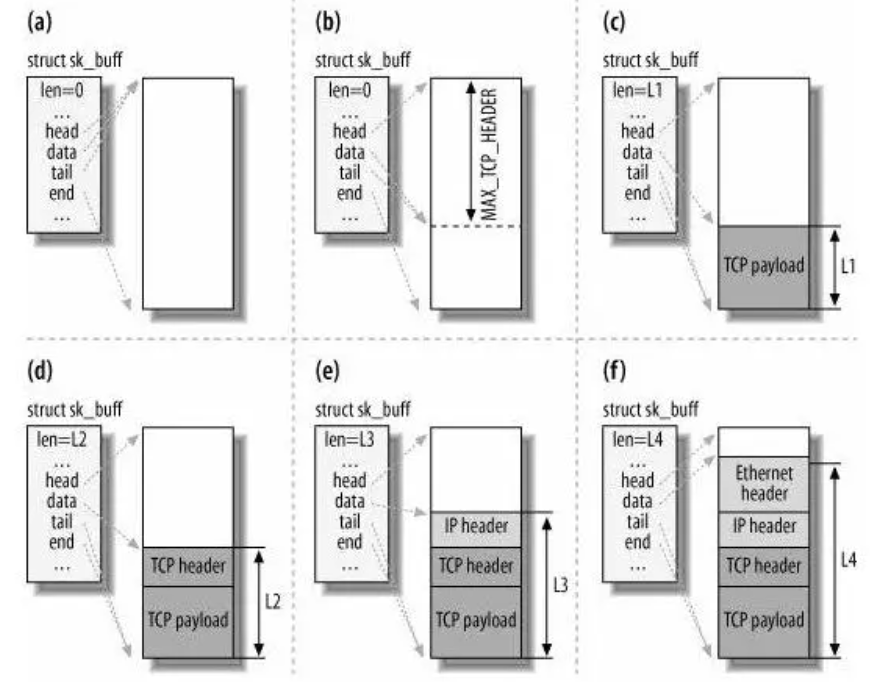
这张图片描述的是网络数据包在发送过程中,struct sk_buff结构体中的data指针的移动过程。struct sk_buff是Linux内核网络子系统中使用的一种数据结构,用于表示网络帧(frame)或包(packet)。以下是对图片中流程的解释:
(a) 初始状态:
struct sk_buff结构体被创建,len(长度)设置为0,表示还没有数据。head指向数据包的开始,end和tail指向数据包的结束。(b) 数据开始填充:数据被添加到
struct sk_buff中,len增加,data指针移动到新数据的开始位置,但tail和end指针保持不变。(c) 数据填充继续:更多的数据被添加,
len继续增加,data指针继续向前移动,指向新添加的数据的开始。(d) 以太网头部添加:以太网头部(Ethernet header)被添加到数据包的开始,
head指针向前移动,data指针也相应移动,tail和end保持不变。这通常包含了目的MAC地址和源MAC地址等信息。(e) IP头部添加:IP头部被添加到以太网头部之后,
head和data指针再次向前移动,tail和end保持不变。IP头部包含了源IP地址和目的IP地址等信息。(f) TCP头部添加:最后,TCP头部被添加到IP头部之后,
head和data指针继续向前移动。TCP头部包含了端口号、序列号等信息。
整个流程描述了从创建一个空的struct sk_buff到逐步添加数据和各个网络层的头部,最终形成一个完整的网络数据包的过程。这个数据包随后会被发送到网络上。在实际的网络编程中,这个结构体是非常关键的,因为它允许动态地添加或修改网络数据包的内容。
信号
发送信号
Linux下,一个进程给其他进程发送信号的API是kill函数; sig是信号,pid是目标进程
|

定时器
定时是指在一段时间之后触发某段代码的机制;我们可以在这段代码中依次处理所有到期的定时器。
Linux提供了三种定时方法
- socket 选项SO_RCVTIMEO 和SO_SNDTIMEO(接收数据超时时间和发送数据超时时间 )
- SIGALRM 信号。
- IO 复用系统调用的超时参数。
加载与存储
1 从内存读取数据到寄存器
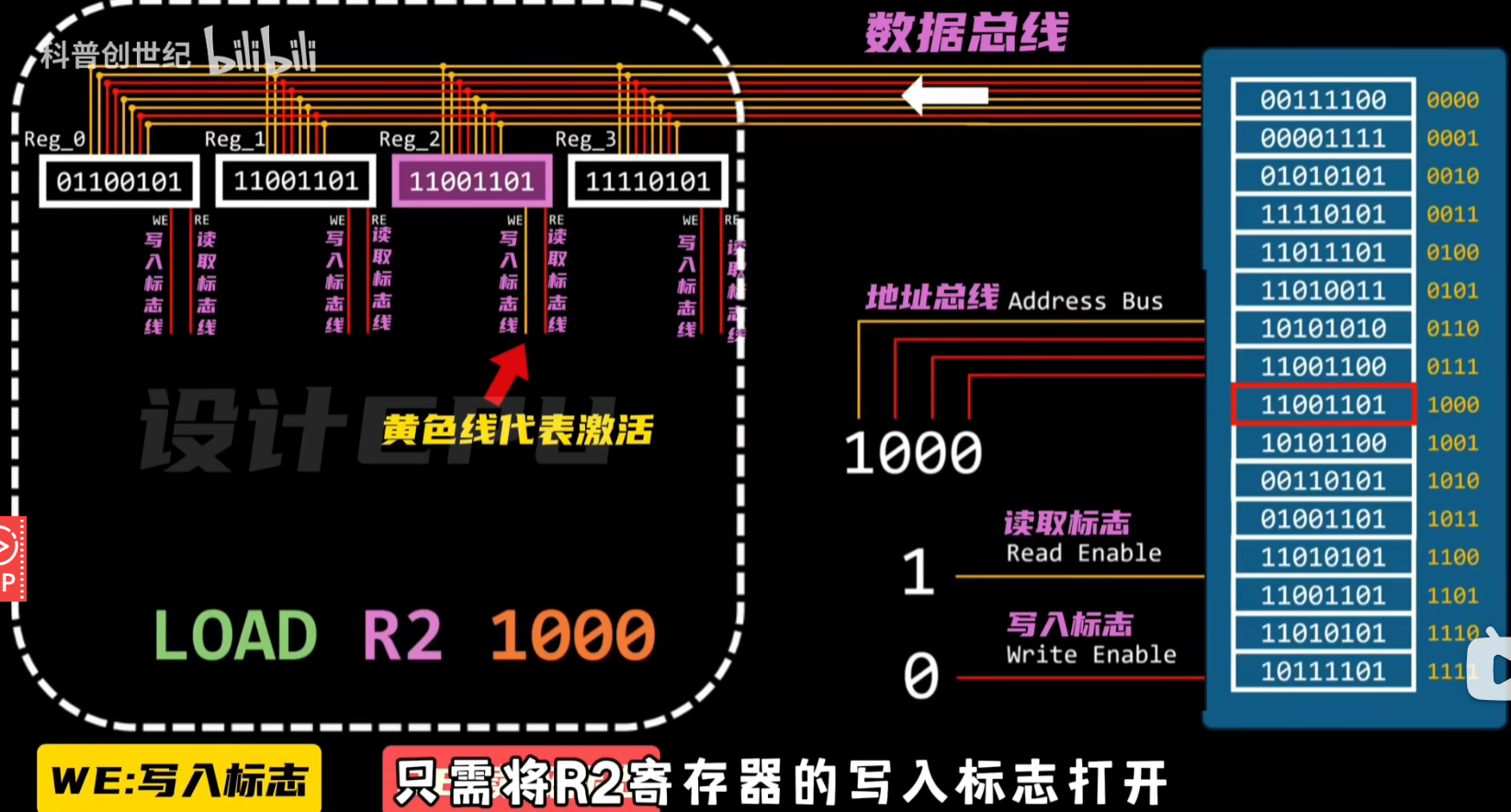
2 将寄存器的数据存到内存
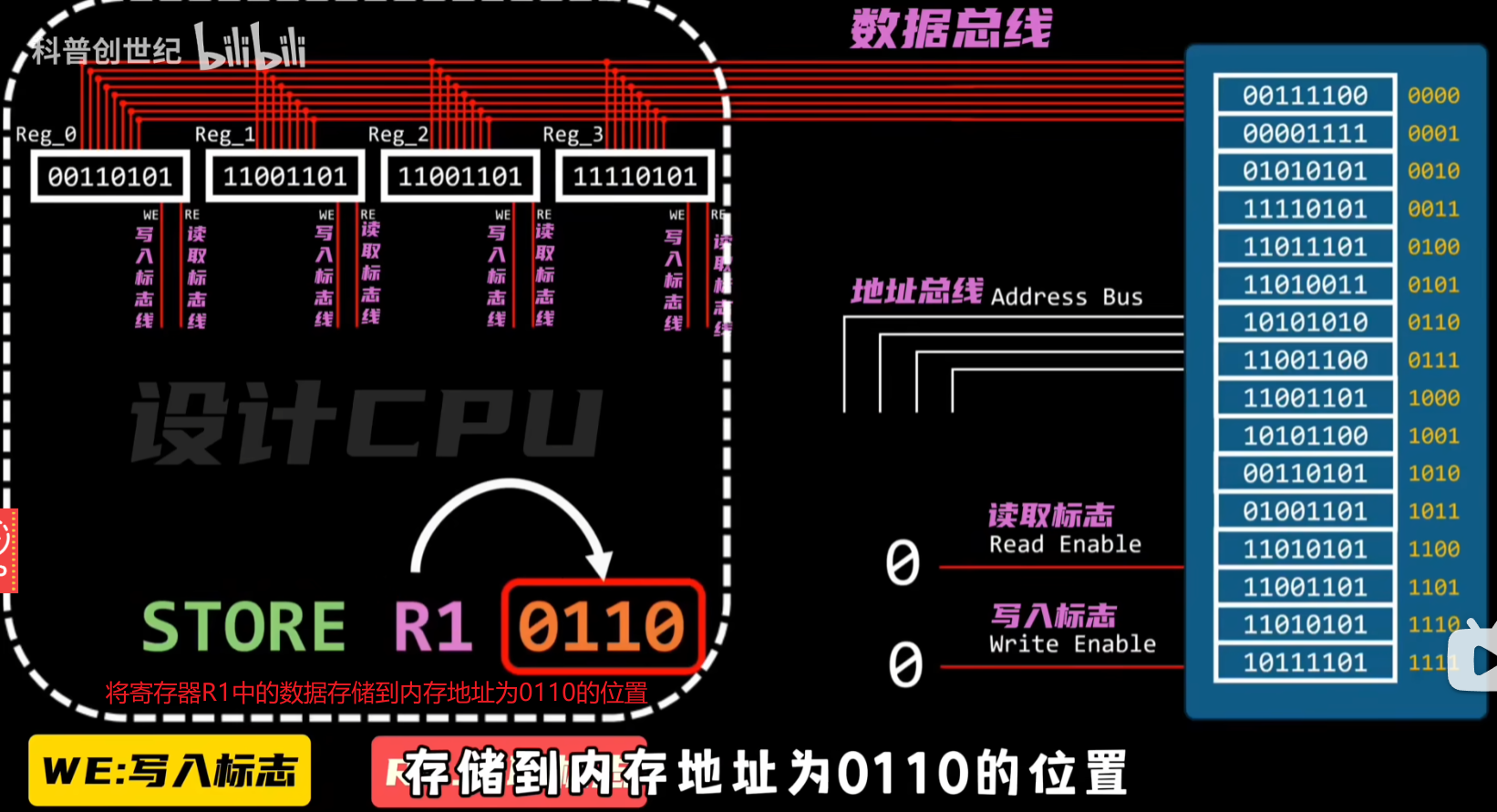
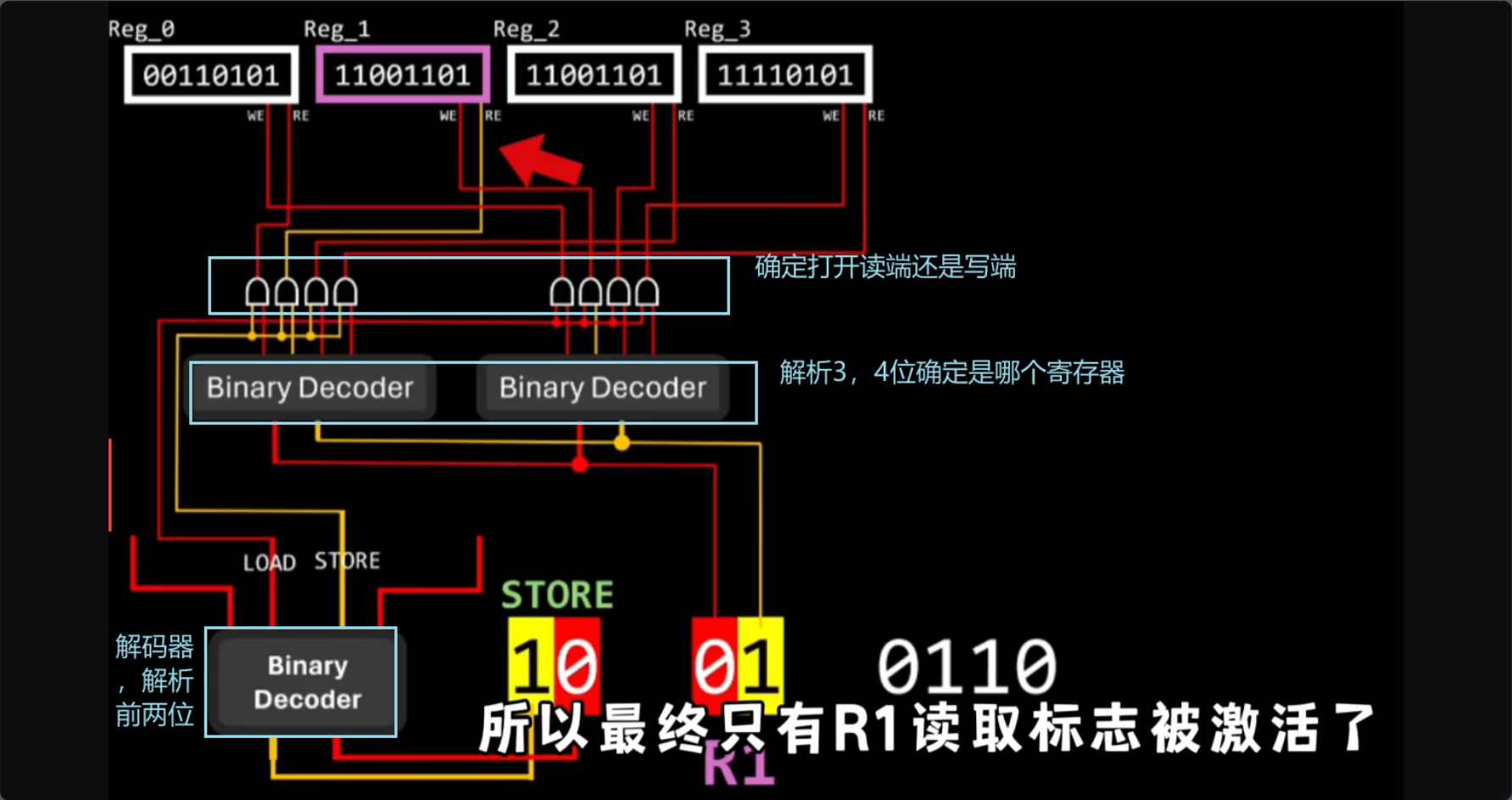
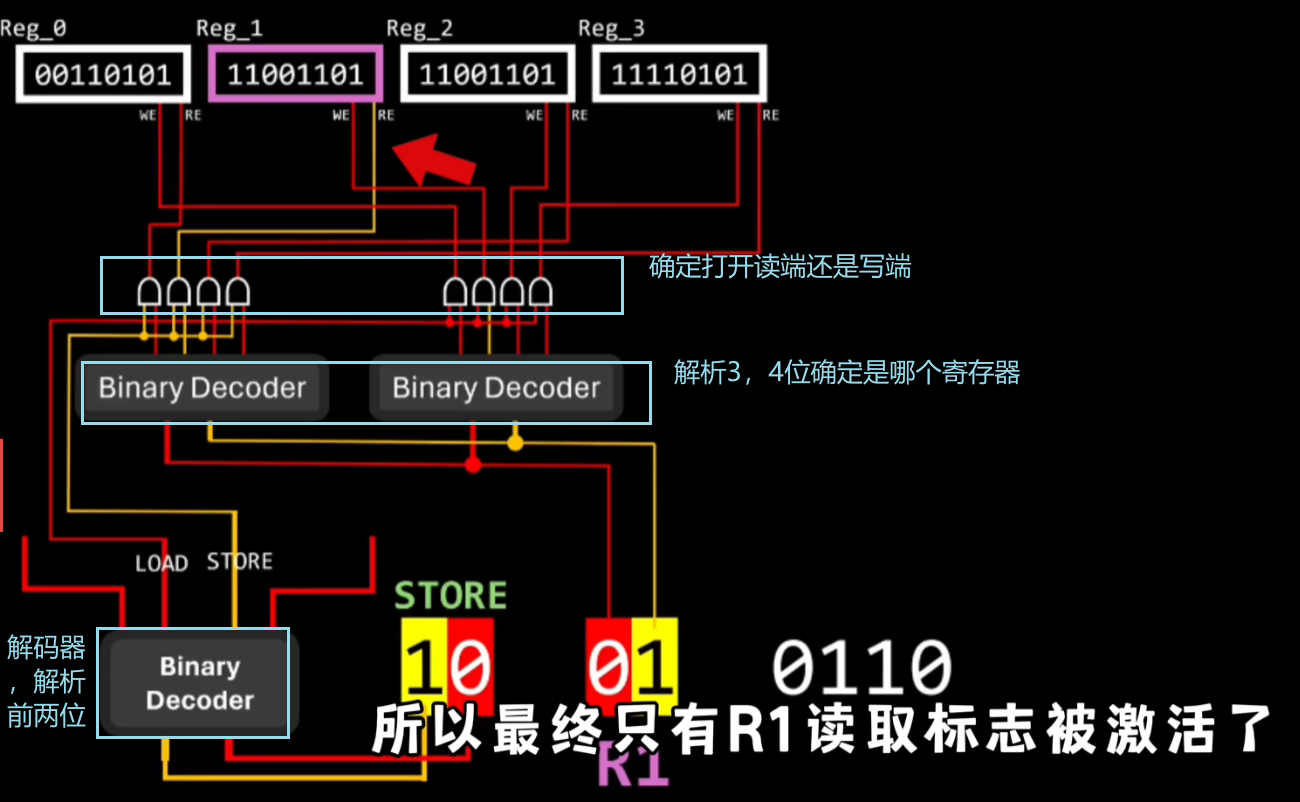
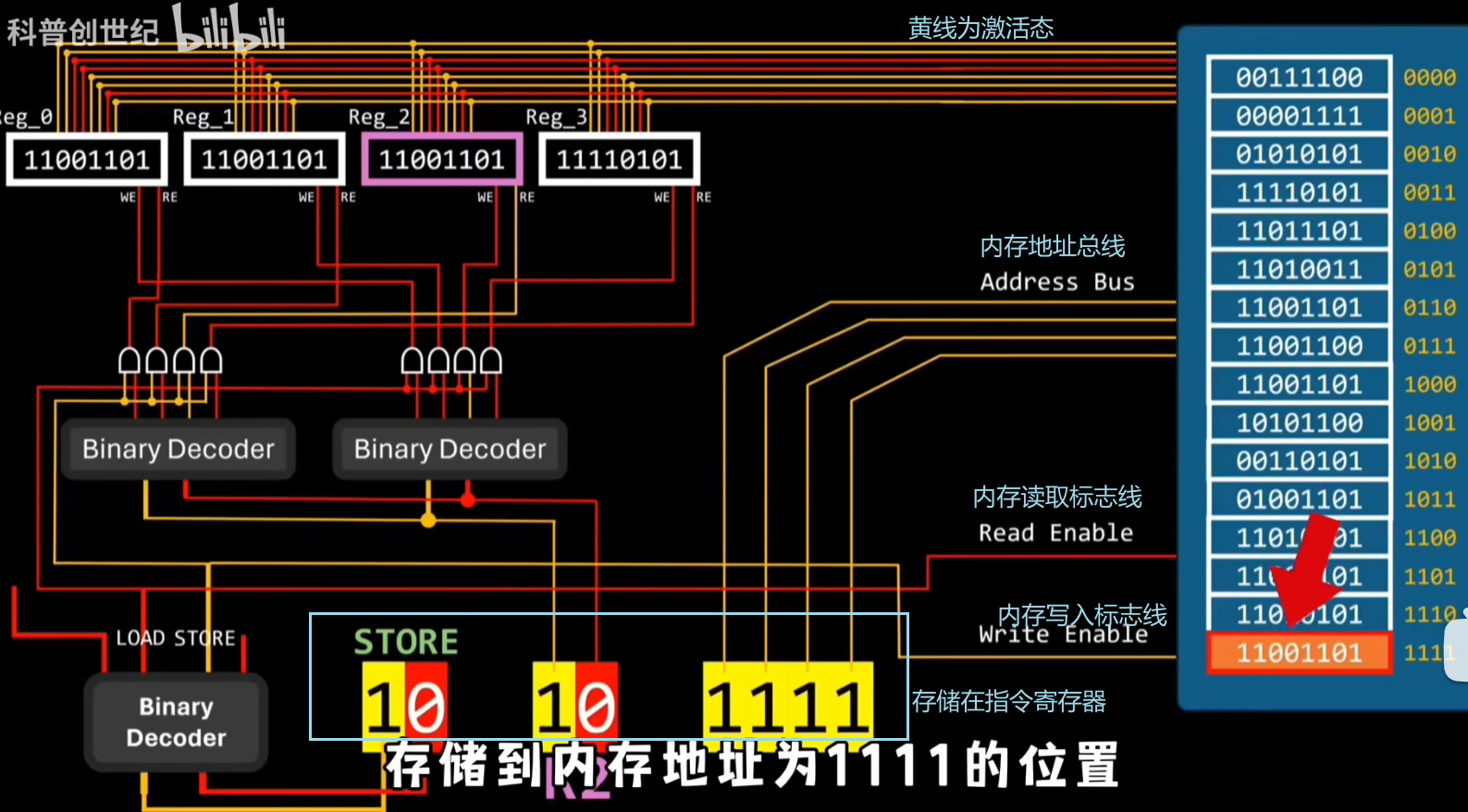
这些读写标志和数据总线都是如何控制的呢?
对于CPU寄存器的读写标志可以用两个解码器来解决,
00表示算数指令,剩下几位图中有解释
01表示加载指令,10代表存储指令,后两位代表加载或存储数据所需的寄存器,最后四位代表要加载或存储数据的内存地址
11表示控制流

运算
算数逻辑单元
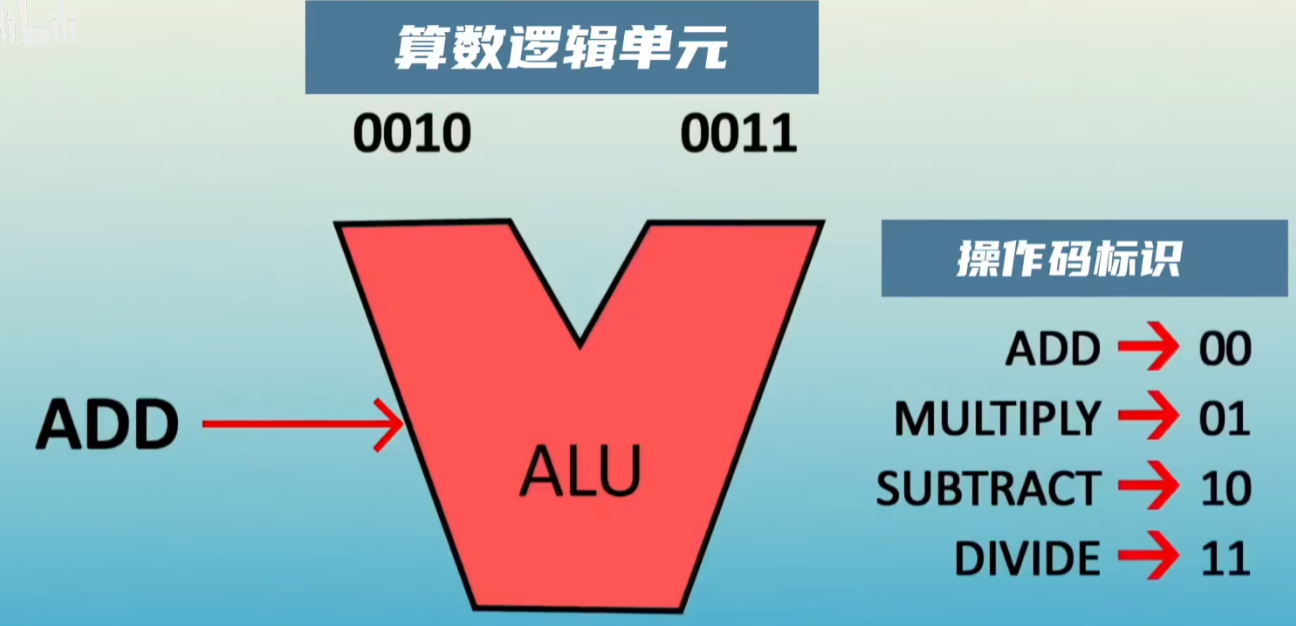
算术运算
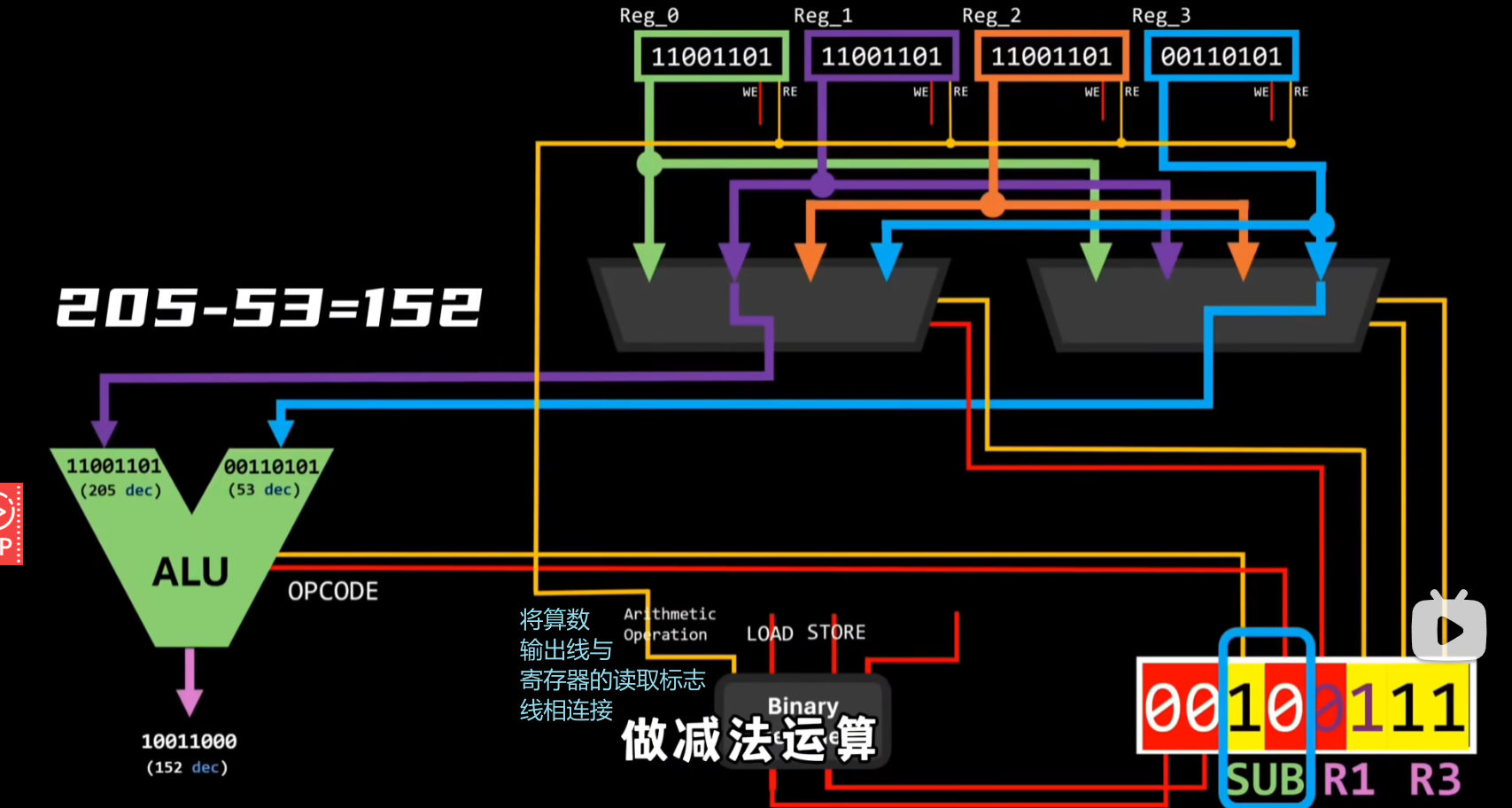
将此简化后的算数运算电路和前面加载和存储电路加入进来,然后再加入其他电路,然后再将整个电路封装起来,这就组成了一个控制单元;
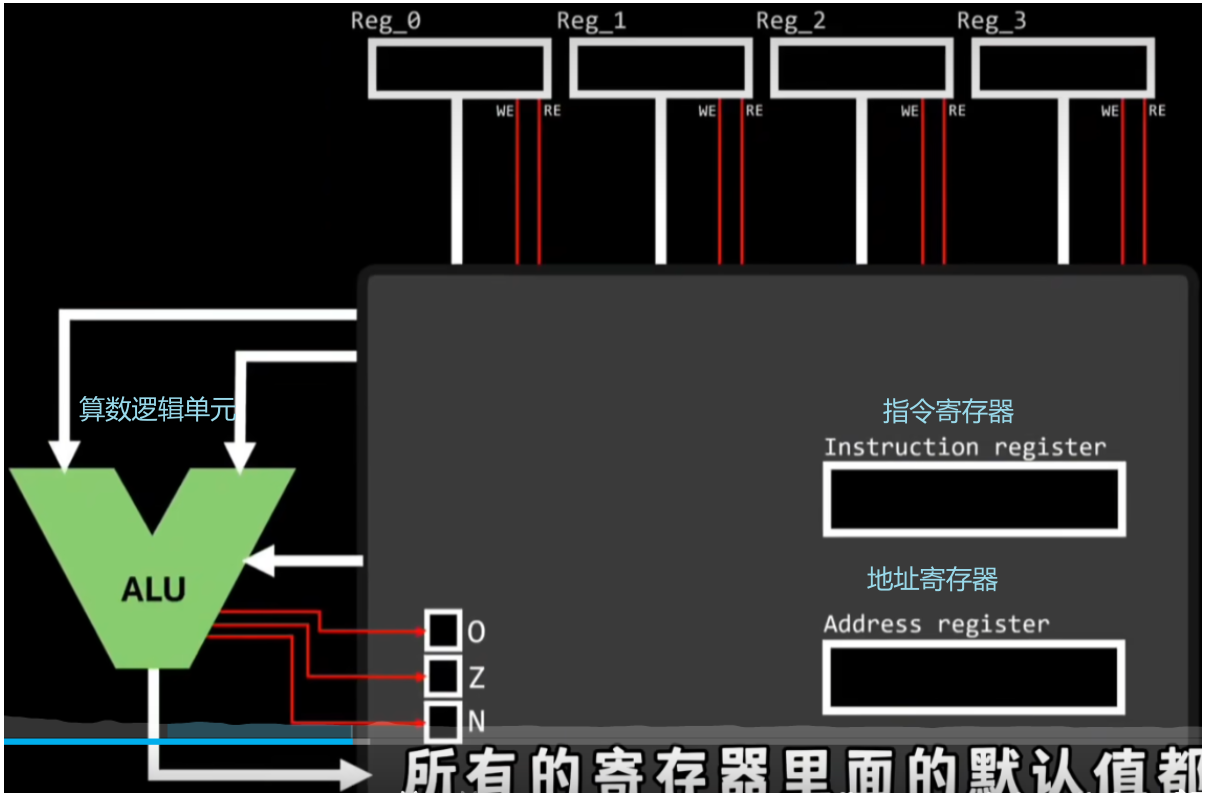
CPU通电后所有寄存器中的值都为默认值零,所以寄存器里的值要从内存中获取;
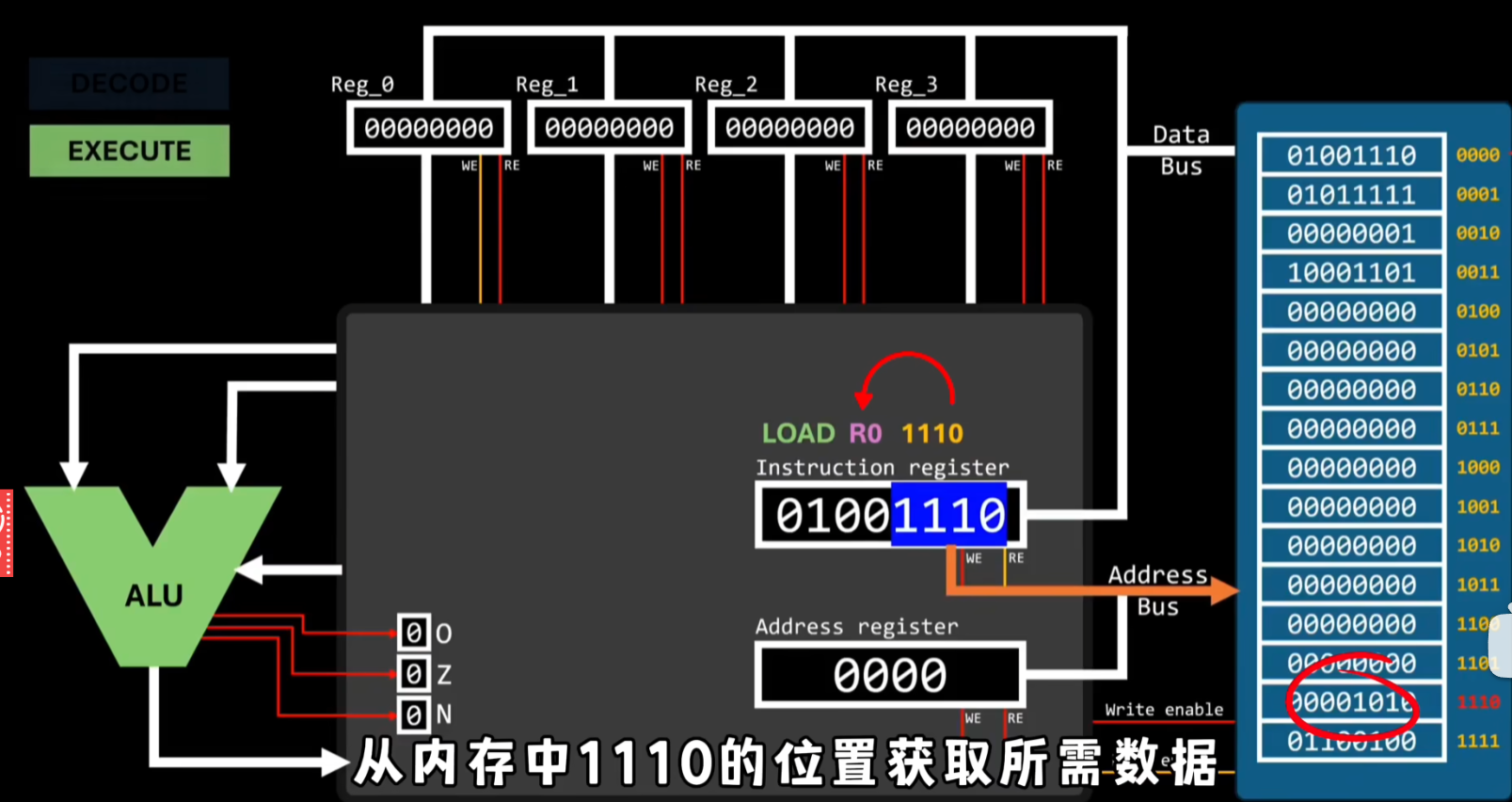
由于地址寄存器的初始值为零所以控制器会从内存地址为0000的位置拿到指令,然后存入指令寄存器中,接着指令寄存器内部的电路就会解析指令寄存器中的指令;
指令01001110的意思是从内存中1110的位置获取所需的数据,然后存入到R0寄存器;执行完后指令寄存器的值会增加1;
然后控制器就会从内存地址为0001的位置拿到指令进行上述操作;
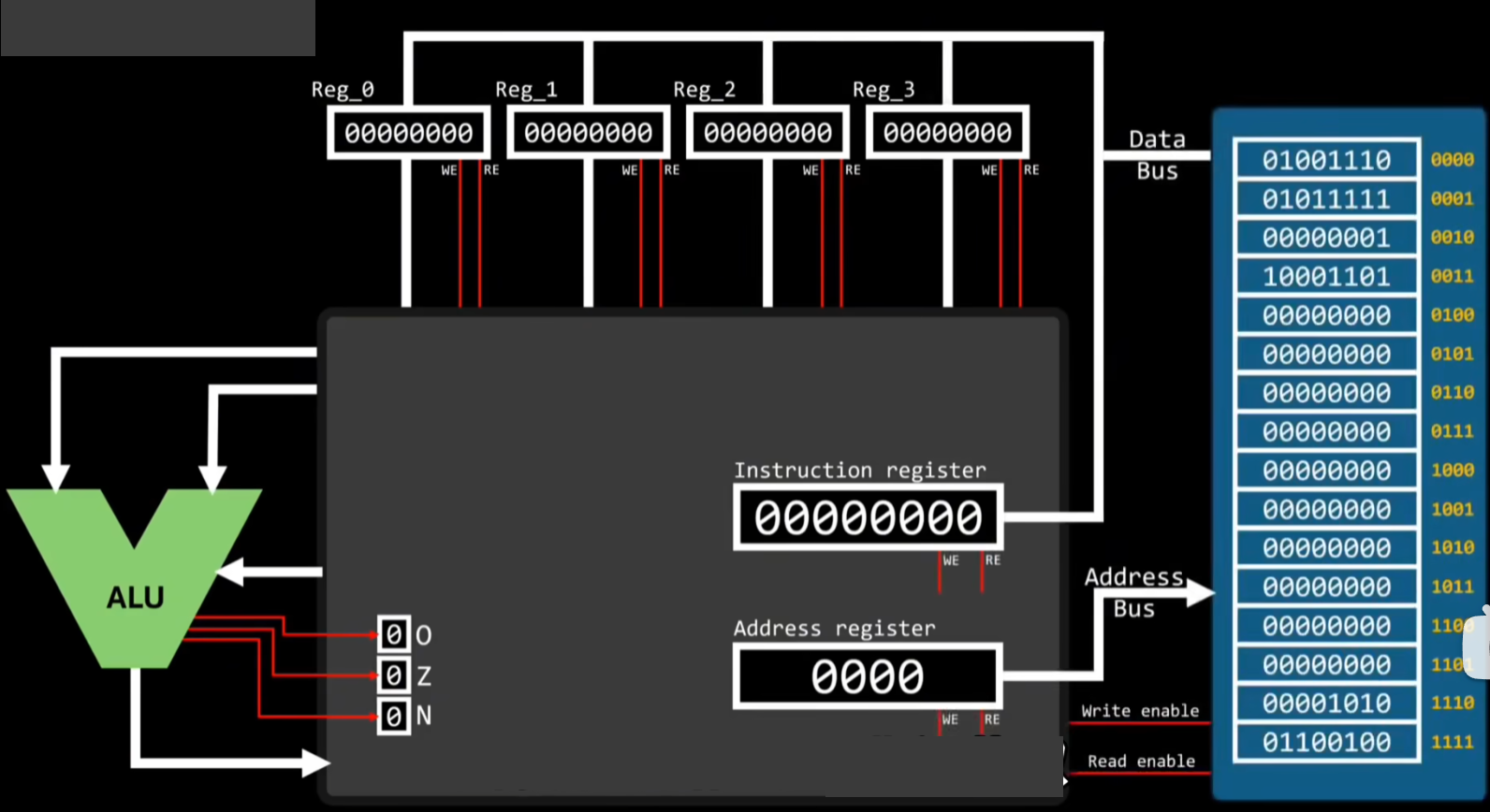
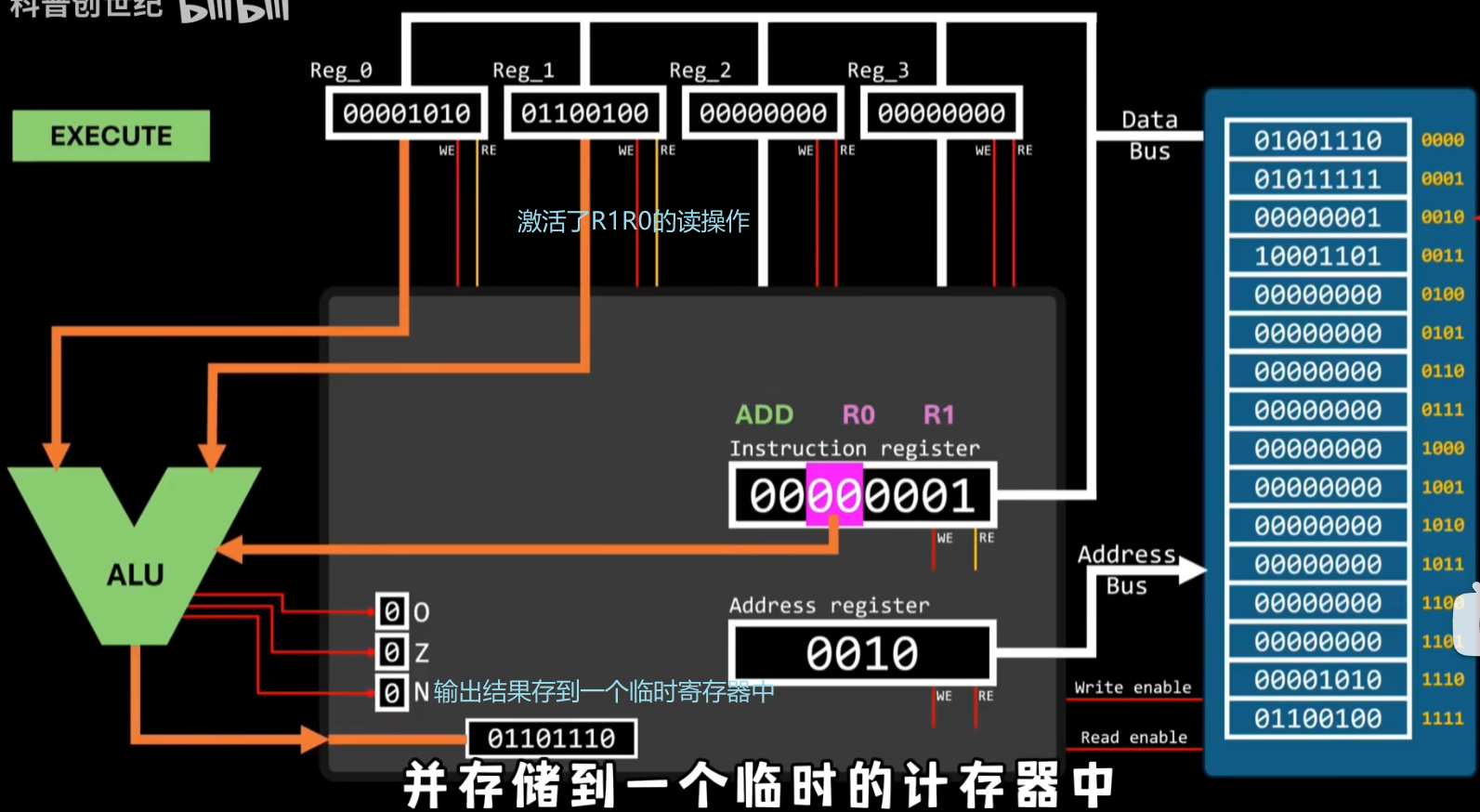
输出的结果存到临时寄存器中再复制到R0寄存器中,后面的指令再存入内存中,到此一次简单的CPU计算才算完成
BIOS用于计算机开机初始过程各种硬件设备的初始化和检测
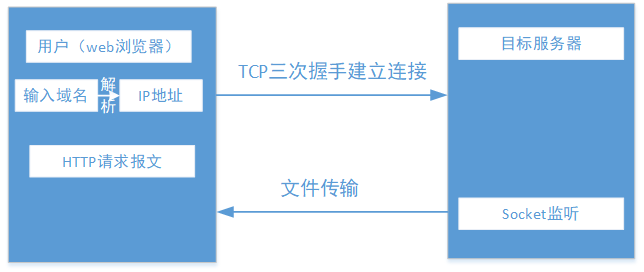
04 Tinyweb
写在最后,学习建议
建议跟一遍原书《Linux高性能服务器编程》游双著
- G:\个人\03电子书、资料\01学习书籍\Linux高性能服务器编程.pdf
源码地址TinyWebServer::fire: Linux下C++轻量级WebServer服务器 - GitCode(里面有社长的文章分析)
9.2 I/O 多路复用:select/poll/epoll | 小林coding (xiaolincoding.com)
【从0开始编写webserver·基础篇#03】TinyWeb源码阅读,还是得看看靠谱的项目 - dayceng - 博客园 (cnblogs.com)
轻量级web并发服务器——TinyWebServer的学习了解_c++_闪耀于终焉之枪-GitCode 开源社区 (csdn.net)
庖丁解牛
近期版本迭代较快,以下内容多以旧版本(raw_version)代码为蓝本进行详解.
- 小白视角:一文读懂社长的TinyWebServer
- 最新版Web服务器项目详解 - 01 线程同步机制封装类
- 最新版Web服务器项目详解 - 02 半同步半反应堆线程池(上)
- 最新版Web服务器项目详解 - 03 半同步半反应堆线程池(下)
- 最新版Web服务器项目详解 - 04 http连接处理(上)
- 最新版Web服务器项目详解 - 05 http连接处理(中)
- 最新版Web服务器项目详解 - 06 http连接处理(下)
- 最新版Web服务器项目详解 - 07 定时器处理非活动连接(上)
- 最新版Web服务器项目详解 - 08 定时器处理非活动连接(下)
- 最新版Web服务器项目详解 - 09 日志系统(上)
- 最新版Web服务器项目详解 - 10 日志系统(下)
- 最新版Web服务器项目详解 - 11 数据库连接池
- 最新版Web服务器项目详解 - 12 注册登录
- 最新版Web服务器项目详解 - 13 踩坑与面试题
- 已更新完毕