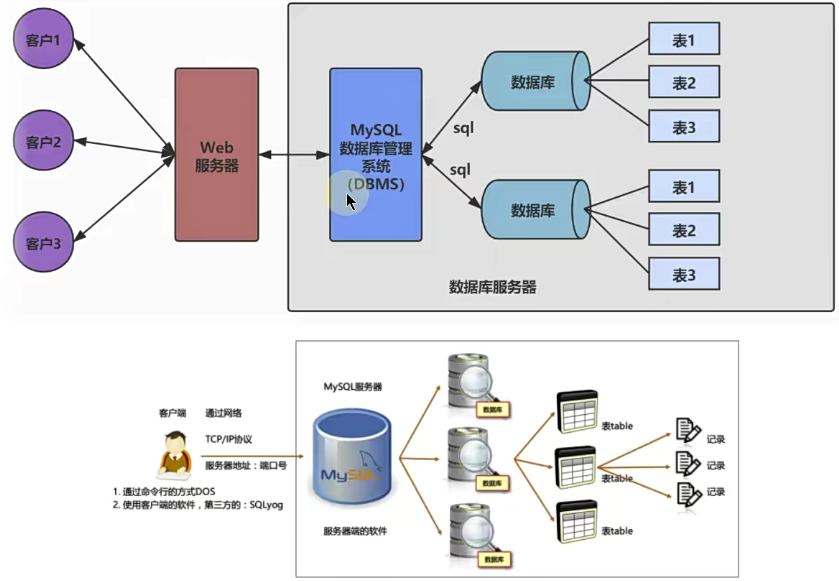
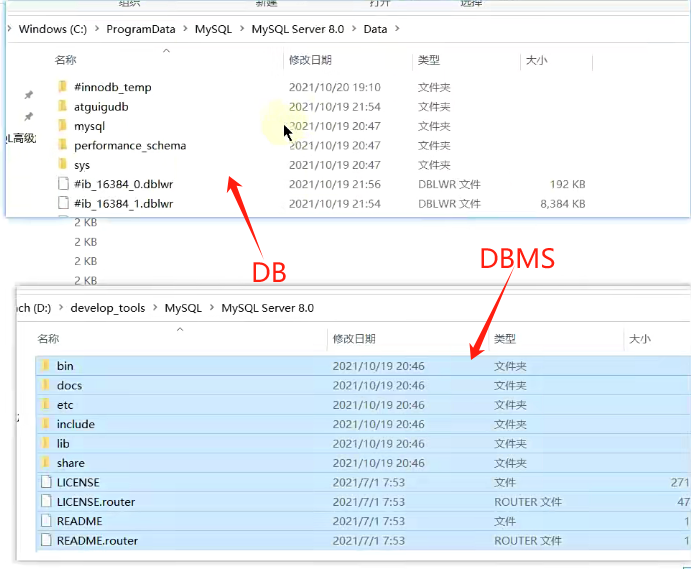
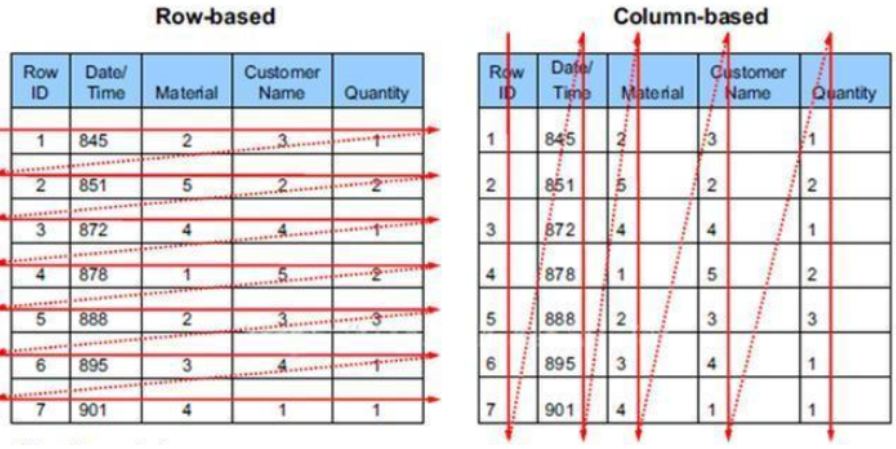
列式数据库是相对于行式存储的数据库(即关系型数据库),Oracle、MySQL、SQL Server 等数据库都是采用的行式存储(Row-based),而列式数据库是将数据按照列存储到数据库中,**这样做的好处是可以大量降低系统的I/O,适合于分布式文件系统,不足在于功能相对有限。典型产品:HBase等。**
DDL:数据定义语言。CREATE \ ALTER \ DROP \ RENAME \ TRUNCATE DML:数据操作语言。INSERT \ DELETE \ UPDATE \ SELECT (重中之重) DCL:数据控制语言。COMMIT \ ROLLBACK \ SAVEPOINT \ GRANT \ REVOKE
SQL语言的规则和规范
2.1 SQL的规则 —-必须要遵守
SQL 可以写在一行或者多行。为了提高可读性,各子句分行写,必要时使用缩进
每条命令以 ; 或 \g 或 \G 结束
关键字不能被缩写也不能分行
关于标点符号
必须保证所有的()、单引号、双引号是成对结束的
必须使用英文状态下的半角输入方式
字符串型和日期时间类型的数据可以使用单引号(’ ‘)表示
列的别名,尽量使用双引号(” “),而且不建议省略as
2.2 SQL的规范 —-建议遵守
MySQL 在 Windows 环境下是大小写不敏感的
MySQL 在 Linux 环境下是大小写敏感的
数据库名、表名、表的别名、变量名是严格区分大小写的
关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的。
推荐采用统一的书写规范:
数据库名、表名、表别名、字段名、字段别名等都小写
SQL 关键字、函数名、绑定变量等都大写
MySQL的三种注释的方式
/* USE dbtest2; -- 这是一个查询语句 SELECT * FROM emp; INSERT INTO emp VALUES(1002,'Tom'); #字符串、日期时间类型的变量需要使用一对''表示 INSERT INTO emp VALUES(1003,'Jerry'); SELECT * FROM emp\G SHOW CREATE TABLE emp\g /*
SELECT ‘尚硅谷’,123,employee_id,last_name FROM employees;
显示表结构
DESCRIBE employees; #显示了表中字段的详细信息
DESC employees;
DESC departments;
过滤数据
#练习:查询90号部门的员工信息 SELECT* FROM employees #过滤条件WHERE,声明在FROM结构的后面 WHERE department_id =90;
#练习:查询last_name为'King'的员工信息 SELECT* FROM EMPLOYEES WHERE LAST_NAME ='King';
运算符
算术运算符: + - * / div % mod
SELECT100, 100+0, 100-0, 100+50, 100+50*30, 100+35.5, 100-35.5 FROM DUAL;
#在SQL中,+没有连接的作用,就表示加法运算。此时,会将字符串转换为数值(隐式转换)
SELECT100+'1' # 在Java语言中,结果是:1001。 FROM DUAL;
SELECT100+'a' #此时将'a'看做0处理 FROM DUAL;
SELECT100+NULL # null值参与运算,结果为null FROM DUAL;
SELECT100, 100*1, 100*1.0, 100/1.0, 100/2, #一般情况下除法是除不尽的,所有SQL默认除法的结果是小 100+2*5/2,100/3, 100 DIV 0 # 分母如果为0,则结果为null FROM DUAL;
#取模运算: % (mod) 结果的符号与被模数一致,被模数%模数
SELECT12%3,12%5, 12 MOD -5,-12%5,-12%-5 FROM DUAL;
#练习:查询员工id为偶数的员工信息 SELECT employee_id,last_name,salary FROM employees WHERE employee_id %2=0;
比较运算符
#2.1=<=><>!=<<=>>=
= 的使用
SELECT1=2,1!=2,1='1',1='a',0='a' #字符串存在隐式转换。如果转换数值不成功,则看做0 FROM DUAL;
SELECT'a'='a','ab'='ab','a'='b' #两边都是字符串的话,则按照ANSI的比较规则进行比较。 FROM DUAL;
SELECT1=NULL,NULL=NULL # 只要有null参与判断,结果就为null FROM DUAL;
SELECT last_name,salary,commission_pct FROM employees #where salary =6000; WHERE commission_pct =NULL; #此时执行,不会有任何的结果
<=>或!= :安全等于。 记忆技巧:为NULL而生。
SELECT1<=>2,1<=>'1',1<=>'a',0<=>'a' FROM DUAL;
SELECT1<=>NULL, NULL<=>NULL FROM DUAL;
#练习:查询表中commission_pct为null的数据有哪些 SELECT last_name,salary,commission_pct FROM employees WHERE commission_pct <=>NULL;
SELECT3<>2,'4'<>NULL, ''!=NULL,NULL!=NULL FROM DUAL;
① IS NULL \ IS NOT NULL \ ISNULL #练习:查询表中commission_pct为null的数据有哪些 SELECT last_name,salary,commission_pct FROM employees WHERE commission_pct IS NULL; #或 SELECT last_name,salary,commission_pct FROM employees WHERE ISNULL(commission_pct);
#练习:查询表中commission_pct不为null的数据有哪些
SELECT last_name,salary,commission_pct FROM employees WHERE commission_pct ISNOTNULL;
#或 SELECT last_name,salary,commission_pct FROM employees WHERENOT commission_pct <=>NULL;
② LEAST() \ GREATEST 最小最大
SELECT LEAST('g','b','t','m'),GREATEST('g','b','t','m') FROM DUAL;
SELECT LEAST(first_name,last_name),LEAST(LENGTH(first_name),LENGTH(last_name)) FROM employees;
③ BETWEEN (条件下界1) AND (条件上界2) (查询条件1和条件2范围内的数据,包含边界) 查询工资在6000 到 8000的员工信息
SELECT employee_id,last_name,salary FROM employees #where salary between6000and8000; WHERE salary >=6000&& salary <=8000;
交换6000 和 8000之后,查询不到数据
SELECT employee_id,last_name,salary FROM employees WHERE salary BETWEEN8000AND6000;
查询工资不在6000 到 8000的员工信息
SELECT employee_id,last_name,salary FROM employees WHERE salary NOTBETWEEN6000AND8000; #where salary <6000or salary >8000;
**#④ in (set)\ not in (set)**离散查找
练习:查询部门为10,20,30部门的员工信息
SELECT last_name,salary,department_id FROM employees #where department_id =10or department_id =20or department_id =30; WHERE department_id IN (10,20,30);
练习:查询工资不是6000,7000,8000的员工信息
SELECT last_name,salary,department_id FROM employees WHERE salary NOTIN (6000,7000,8000);
⑤ LIKE :模糊查询
% : 代表不确定个数的字符 (0个,1个,或多个)
练习:查询last_name中包含字符’a’的员工信息
SELECT last_name FROM employees WHERE last_name LIKE'%a%';
练习:查询last_name中以字符’a’开头的员工信息
SELECT last_name FROM employees WHERE last_name LIKE'a%';
练习:查询last_name中包含字符’a’且包含字符’e’的员工信息
#写法1: SELECT last_name FROM employees WHERE last_name LIKE'%a%'AND last_name LIKE'%e%'; #写法2: SELECT last_name FROM employees WHERE last_name LIKE'%a%e%'OR last_name LIKE'%e%a%';
_ :代表一个不确定的字符
#练习:查询第3个字符是'a'的员工信息 SELECT last_name FROM employees WHERE last_name LIKE'__a%';
#练习:查询第2个字符是_且第3个字符是'a'的员工信息 #需要使用转义字符: \ SELECT last_name FROM employees WHERE last_name LIKE'_\_a%';
#或者 (了解)ESCAPE'$'表示$为转义 SELECT last_name FROM employees WHERE last_name LIKE'_$_a%'ESCAPE'$';
/* SELECT ...,....,.... FROM .... WHERE .... AND / OR / NOT.... ORDER BY .... (ASC/DESC),....,... LIMIT ...,... */
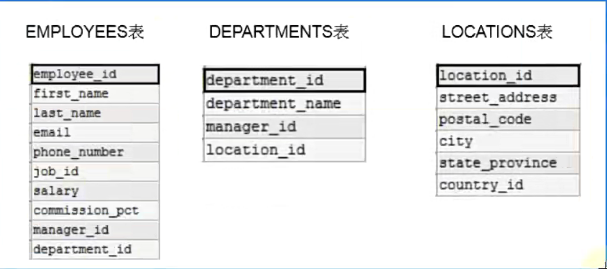
🚩熟悉常见的几个表
DESC employees;
DESC departments;
DESC locations;
🚩查询员工名为’Abel’的人在哪个城市工作?
SELECT* FROM employees WHERE last_name ='Abel';
SELECT* FROM departments WHERE department_id =80;
SELECT* FROM locations WHERE location_id =2500;
🚩出现笛卡尔积的错误
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。组合的个数即为两个集合中元素个数的乘积数。
⛔错误的原因:缺少了多表的连接条件
错误的实现方式:每个员工都与每个部门匹配了一遍。 SELECT employee_id,department_name FROM employees,departments; #查询出2889条记录
#错误的方式 SELECT employee_id,department_name FROM employees CROSSJOIN departments;#查询出2889条记录
SELECT* FROM employees; #107条记录
SELECT2889/107 FROM DUAL;
SELECT* FROM departments; # 27条记录
🚩多表查询的正确方式:需要有连接条件
SELECT employee_id,department_name FROM employees,departments #两个表的连接条件 WHERE employees.`department_id` = departments.department_id;
🚩如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表。
SELECT employees.employee_id,departments.department_name,employees.department_id FROM employees,departments WHERE employees.`department_id` = departments.department_id;
#建议:从sql优化的角度,建议多表查询时,每个字段前都指明其所在的表。
🚩可以给表起别名,在SELECT和WHERE中使用表的别名。
SELECT emp.employee_id,dept.department_name,emp.department_id FROM employees emp,departments dept WHERE emp.`department_id` = dept.department_id;
❗❗#如果给表起了别名,一旦在SELECT或WHERE中使用表名的话,则必须使用表的别名,而不能再使用表的原名。 #如下的操作是错误的: SELECT emp.employee_id,departments.department_name,emp.department_id FROM employees emp,departments dept WHERE emp.`department_id` = departments.department_id;
🚩结论:如果有n个表实现多表的查询,则需要至少n-1个连接条件
#练习:查询员工的employee_id,last_name,department_name,city SELECT e.employee_id,e.last_name,d.department_name,l.city,e.department_id,l.location_id FROM employees e,departments d,locations l WHERE e.`department_id` = d.`department_id` AND d.`location_id` = l.`location_id`;
/* 角度1:等值连接 vs 非等值连接 角度2:自连接 vs 非自连接 角度3:内连接 vs 外连接 */
等值连接 vs 非等值连接
🚩非等值连接的例子:
SELECT* FROM job_grades;
SELECT e.last_name,e.salary,j.grade_level FROM employees e,job_grades j #where e.`salary` between j.`lowest_sal` and j.`highest_sal`; WHERE e.`salary` >= j.`lowest_sal` AND e.`salary` <= j.`highest_sal`;
🚩 自连接 vs 非自连接
SELECT*FROM employees;
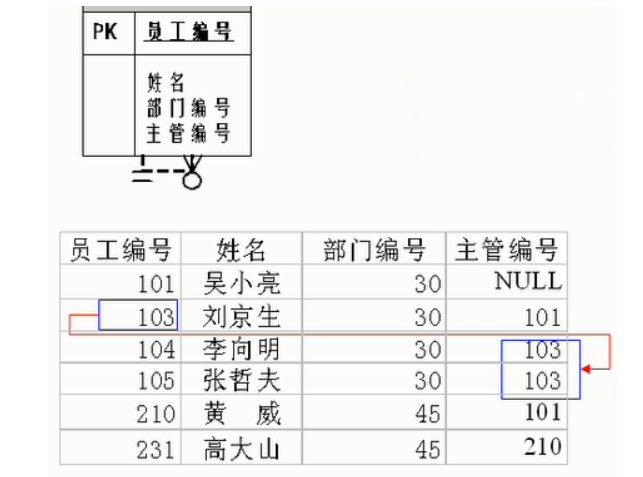
自连接的例子: #练习:查询员工id,员工姓名及其管理者的id和姓名
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name FROM employees emp ,employees mgr WHERE emp.`manager_id` = mgr.`employee_id`;
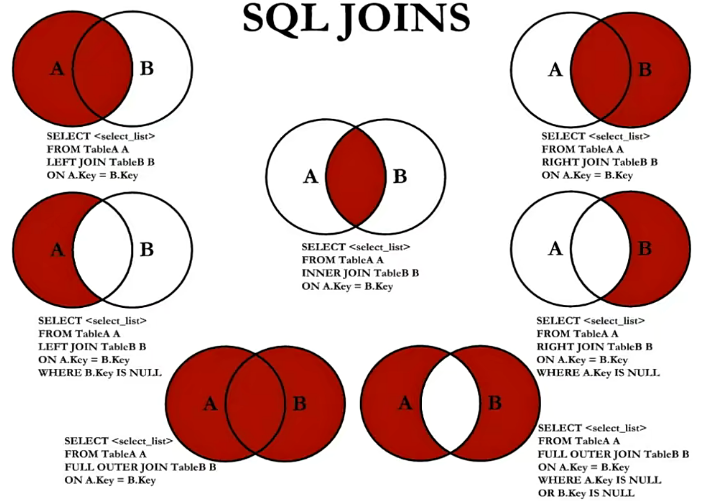
🚩 内连接 vs 外连接
内连接:合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
SELECT employee_id,department_name FROM employees e,departments d WHERE e.department_id = d.department_id; # 只有106条记录
SELECT last_name,department_name FROM employees e INNERJOIN departments d ON e.`department_id` = d.`department_id`; 多表连接 SELECT last_name,department_name,city FROM employees e JOIN departments d ON e.`department_id` = d.`department_id` JOIN locations l ON d.`location_id` = l.`location_id`;
SQL99语法实现外连接:
练习:查询所有的员工的last_name,department_name信息
🚩左外连接:
SELECT last_name,department_name FROM employees e LEFTJOIN departments d ON e.`department_id` = d.`department_id`;
🚩右外连接: SELECT last_name,department_name FROM employees e RIGHTOUTERJOIN departments d ON e.`department_id` = d.`department_id`;
🚩满外连接:mysql不支持FULLOUTERJOIN SELECT last_name,department_name FROM employees e FULLOUTERJOIN departments d ON e.`department_id` = d.`department_id`;
SELECT employee_id,department_name FROM employees e JOIN departments d ON e.`department_id` = d.`department_id`;
🥇左上图:左外连接
SELECT employee_id,department_name FROM employees e LEFTJOIN departments d ON e.`department_id` = d.`department_id`;
🥇右上图:右外连接
SELECT employee_id,department_name FROM employees e RIGHTJOIN departments d ON e.`department_id` = d.`department_id`;
🥇左中图:
SELECT employee_id,department_name FROM employees e LEFTJOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` ISNULL;
🥇右中图:
SELECT employee_id,department_name FROM employees e RIGHTJOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` ISNULL;
🥇左下图:满外连接
🥇方式1:左上图 UNIONALL 右中图
SELECT employee_id,department_name FROM employees e LEFTJOIN departments d ON e.`department_id` = d.`department_id` UNIONALL SELECT employee_id,department_name FROM employees e RIGHTJOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` ISNULL;
🥇方式2:左中图 UNIONALL 右上图
SELECT employee_id,department_name FROM employees e LEFTJOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` ISNULL UNIONALL SELECT employee_id,department_name FROM employees e RIGHTJOIN departments d ON e.`department_id` = d.`department_id`;
🥇右下图:左中图 UNIONALL 右中图
SELECT employee_id,department_name FROM employees e LEFTJOIN departments d ON e.`department_id` = d.`department_id` WHERE d.`department_id` ISNULL UNIONALL SELECT employee_id,department_name FROM employees e RIGHTJOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` ISNULL;
🚩 SQL99语法的新特性1:自然连接NATURAL JOIN
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.`department_id` = d.`department_id` AND e.`manager_id` = d.`manager_id`;#连接条件有两个
NATURALJOIN : 它会帮你自动查询两张连接表中`所有相同的字段`,然后进行`等值连接`。
SELECT employee_id,last_name,department_name FROM employees e NATURALJOIN departments d;
🚩SQL99语法的新特性2:USING
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.department_id = d.department_id;
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d USING (department_id);
🚩拓展:
SELECT last_name,job_title,department_name FROM employees INNERJOIN departments INNERJOIN jobs ON employees.department_id = departments.department_id AND employees.job_id = jobs.job_id;
小结
表连接的约束条件可以有三种方式:WHERE, ON, USING
WHERE:适用于所有关联查询
ON :只能和JOIN一起使用,只能写关联条件。虽然关联条件可以并到WHERE中和其他条件一起写,但分开写可读性更好。
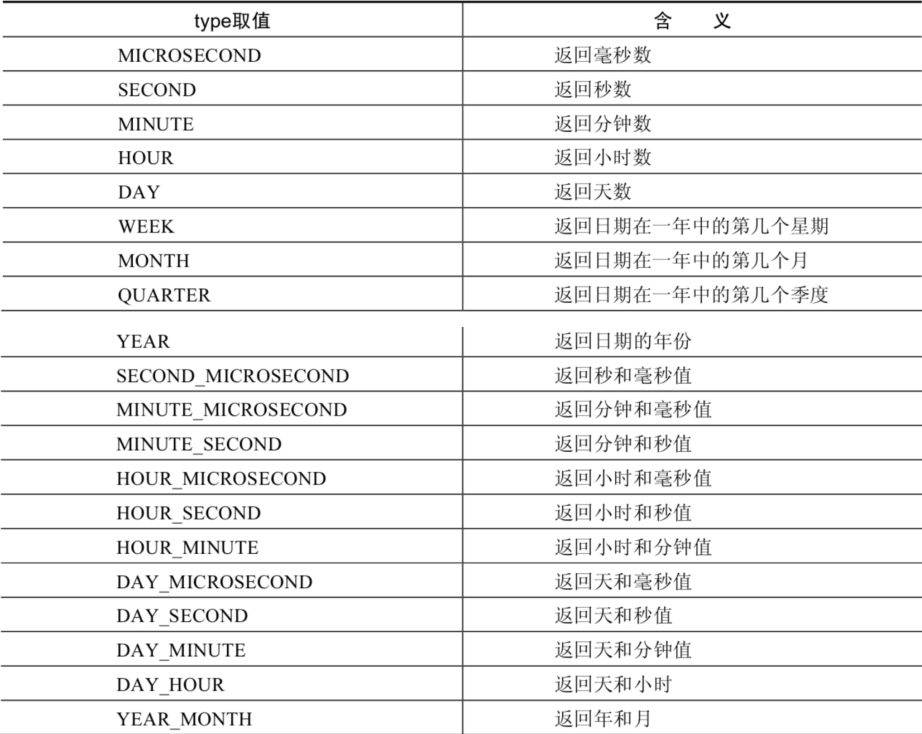
SELECT NOW(),DATE_ADD(NOW(),INTERVAL1YEAR), DATE_ADD(NOW(),INTERVAL-1YEAR), DATE_SUB(NOW(),INTERVAL1YEAR) FROM DUAL;
SELECT DATE_ADD(NOW(), INTERVAL1DAY) AS col1,DATE_ADD('2021-10-21 23:32:12',INTERVAL1SECOND) AS col2, ADDDATE('2021-10-21 23:32:12',INTERVAL1SECOND) AS col3, DATE_ADD('2021-10-21 23:32:12',INTERVAL'1_1' MINUTE_SECOND) AS col4, DATE_ADD(NOW(), INTERVAL-1YEAR) AS col5, #可以是负数 DATE_ADD(NOW(), INTERVAL'1_1' YEAR_MONTH) AS col6 #需要单引号 FROM DUAL;
SELECT ADDTIME(NOW(),20),SUBTIME(NOW(),30),SUBTIME(NOW(),'1:1:3'),DATEDIFF(NOW(),'2021-10-01'), TIMEDIFF(NOW(),'2021-10-25 22:10:10'),FROM_DAYS(366),TO_DAYS('0000-12-25'), LAST_DAY(NOW()),MAKEDATE(YEAR(NOW()),32),MAKETIME(10,21,23),PERIOD_ADD(20200101010101,10) FROM DUAL;
💖日期的格式化与解析
函数
用法
DATE_FORMAT(date,fmt)
按照字符串fmt格式化日期date值为字符串
TIME_FORMAT(time,fmt)
按照字符串fmt格式化时间time值
GET_FORMAT(date_type,format_type)
返回日期字符串的显示格式
STR_TO_DATE(str, fmt)
按照字符串fmt对str进行解析,解析为一个日期
上述 非GET_FORMAT 函数中fmt参数常用的格式符:
符
说明
格式符
说明
%Y
4位数字表示年份
%y
表示两位数字表示年份
%M
月名表示月份(January,….)
%m
两位数字表示月份(01,02,03。。。)
%b
缩写的月名(Jan.,Feb.,….)
%c
数字表示月份(1,2,3,…)
%D
英文后缀表示月中的天数(1st,2nd,3rd,…)
%d
两位数字表示月中的天数(01,02…)
%e
数字形式表示月中的天数(1,2,3,4,5…..)
%H
两位数字表示小数,24小时制(01,02..)
%h和%I
两位数字表示小时,12小时制(01,02..)
%k
数字形式的小时,24小时制(1,2,3)
%l
数字形式表示小时,12小时制(1,2,3,4….)
%i
两位数字表示分钟(00,01,02)
%S和%s
两位数字表示秒(00,01,02…)
%W
一周中的星期名称(Sunday…)
%a
一周中的星期缩写(Sun., Mon.,Tues.,..)
%w
以数字表示周中的天数(0=Sunday,1=Monday….)
%j
以3位数字表示年中的天数(001,002…)
%U
以数字表示年中的第几周, (1,2,3。。)其中Sunday为周中第一天
%u
以数字表示年中的第几周, (1,2,3。。)其中Monday为周中第一天
%T
24小时制
%r
12小时制
%p
AM或PM
%%
表示%
格式化:日期 ---> 字符串
解析: 字符串 ----> 日期
#此时我们谈的是日期的显式格式化和解析
#之前,我们接触过隐式的格式化或解析 SELECT* FROM employees WHERE hire_date ='1993-01-13';
SELECT last_name,commission_pct,IFNULL(commission_pct,0) "details" FROM employees;
CASE WHEN … THEN …WHEN … THEN … ELSE … END
类似于java的if ... else if ... else if ... else
SELECT last_name,salary,CASEWHEN salary >=15000THEN'白骨精' WHEN salary >=10000THEN'潜力股' WHEN salary >=8000THEN'小屌丝' ELSE'草根'END "details",department_id FROM employees;
SELECT last_name,salary,CASEWHEN salary >=15000THEN'白骨精' WHEN salary >=10000THEN'潜力股' WHEN salary >=8000THEN'小屌丝' END "details" FROM employees;
#正确的写法: SELECT department_id,MAX(salary) FROM employees GROUPBY department_id HAVINGMAX(salary) >10000;
#要求3:开发中,我们使用HAVING的前提是SQL中使用了GROUPBY。
#练习:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息 #方式1:推荐,执行效率高于方式2. SELECT department_id,MAX(salary) FROM employees WHERE department_id IN (10,20,30,40) GROUPBY department_id HAVINGMAX(salary) >10000;
#方式2: SELECT department_id,MAX(salary) FROM employees GROUPBY department_id HAVINGMAX(salary) >10000AND department_id IN (10,20,30,40);
/* WHERE 与 HAVING 的对比 1. 从适用范围上来讲,HAVING的适用范围更广。 2. 如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING */
SQL底层执行原理
#4.1SELECT 语句的完整结构 /* #sql92语法: SELECT ....,....,....(存在聚合函数) FROM ...,....,.... WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件 GROUP BY ...,.... HAVING 包含聚合函数的过滤条件 ORDER BY ....,...(ASC / DESC ) LIMIT ...,.... #sql99语法: SELECT ....,....,....(存在聚合函数) FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件 (LEFT / RIGHT)JOIN ... ON .... WHERE 不包含聚合函数的过滤条件 GROUP BY ...,.... HAVING 包含聚合函数的过滤条件 ORDER BY ....,...(ASC / DESC ) LIMIT ...,.... */
SQL语句的执行过程:
#FROM …,…-> ON -> (LEFT/RIGNT JOIN) -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT ->ORDER BY -> LIMIT
子查询
由一个具体的需求,引入子查询
#需求:谁的工资比Abel的高? #方式1: SELECT salary FROM employees WHERE last_name ='Abel';
SELECT last_name,salary FROM employees WHERE salary >11000;
#方式2:自连接 SELECT e2.last_name,e2.salary FROM employees e1,employees e2 WHERE e2.`salary` > e1.`salary` #多表的连接条件 AND e1.last_name ='Abel';
#方式3:子查询 SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name ='Abel' );
SELECT last_name,job_id,salary FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id =141 ) AND salary > ( SELECT salary FROM employees WHERE employee_id =143 );
#题目:返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name,job_id,salary FROM employees WHERE salary = ( SELECTMIN(salary) FROM employees );
#题目:查询与141号员工的manager_id和department_id相同的其他员工 #的employee_id,manager_id,department_id。 #方式1: SELECT employee_id,manager_id,department_id FROM employees WHERE manager_id = ( SELECT manager_id FROM employees WHERE employee_id =141 ) AND department_id = ( SELECT department_id FROM employees WHERE employee_id =141 ) AND employee_id <>141;//员工id不等于141
#方式2:了解 SELECT employee_id,manager_id,department_id FROM employees WHERE (manager_id,department_id) = ( SELECT manager_id,department_id FROM employees WHERE employee_id =141 ) AND employee_id <>141;
#题目:查询最低工资大于110号部门最低工资的部门id和其最低工资
SELECT department_id,MIN(salary) FROM employees WHERE department_id ISNOTNULL GROUPBY department_id HAVINGMIN(salary) > ( SELECTMIN(salary) FROM employees WHERE department_id =110 );
SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id =1800) THEN'Canada' ELSE'USA'END "location" FROM employees;
子查询中的空值问题
SELECT last_name, job_id FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE last_name ='Haas');
非法使用子查询
#错误:Subquery returns more than 1row SELECT employee_id, last_name FROM employees WHERE salary = (SELECTMIN(salary) FROM employees GROUPBY department_id);
多行子查询
多行子查询的操作符: IN ANY ALL SOME(同ANY)
操作符
含义
IN
等于列表中的任意一个
ANY
需要和单行比较操作符一起使用,和子查询返回的某一/任一个值比较
ALL
需要和单行比较操作符一起使用,和子查询返回的所有值比较
SOME
实际上是ANY的别名,作用相同,一般常使用ANY
举例:
IN:
SELECT employee_id, last_name FROM employees WHERE salary IN (SELECTMIN(salary) FROM employees GROUPBY department_id);
SELECT employee_id,last_name,job_id,salary FROM employees WHERE job_id <>'IT_PROG' AND salary <ANY ( SELECT salary FROM employees WHERE job_id ='IT_PROG' );
#题目:返回其它job_id中比job_id为‘IT_PROG’部门所有工资低的员工的员工号、 #姓名、job_id 以及salary SELECT employee_id,last_name,job_id,salary FROM employees WHERE job_id <>'IT_PROG' AND salary <ALL ( SELECT salary FROM employees WHERE job_id ='IT_PROG' ); #题目:查询平均工资最低的部门id #MySQL中聚合函数是不能嵌套使用的。 #方式1: SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary) = ( SELECTMIN(avg_sal) FROM( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id ) t_dept_avg_sal );
#方式2: SELECT department_id FROM employees GROUPBY department_id HAVINGAVG(salary) <=ALL( SELECTAVG(salary) avg_sal FROM employees GROUPBY department_id )
5.3 空值问题
SELECT last_name FROM employees WHERE employee_id NOTIN ( SELECT manager_id FROM employees );
SELECT last_name,salary,department_id FROM employees WHERE salary > ( SELECTAVG(salary) FROM employees ); #题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id #方式1:使用相关子查询 SELECT last_name,salary,department_id FROM employees e1 WHERE salary > ( SELECTAVG(salary) FROM employees e2 WHERE department_id = e1.`department_id` );
#方式2:在FROM中声明子查询 SELECT e.last_name,e.salary,e.department_id FROM employees e,( SELECT department_id,AVG(salary) avg_sal FROM employees GROUPBY department_id) t_dept_avg_sal WHERE e.department_id = t_dept_avg_sal.department_id AND e.salary > t_dept_avg_sal.avg_sal
#题目:查询员工的id,salary,按照department_name 排序
SELECT employee_id,salary FROM employees e ORDERBY ( SELECT department_name FROM departments d WHERE e.`department_id` = d.`department_id` ) ASC;
#结论:在SELECT中,除了GROUPBY 和 LIMIT之外,其他位置都可以声明子查询! /* SELECT ....,....,....(存在聚合函数) FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件 (LEFT / RIGHT)JOIN ... ON .... WHERE 不包含聚合函数的过滤条件 GROUP BY ...,.... HAVING 包含聚合函数的过滤条件 ORDER BY ....,...(ASC / DESC ) LIMIT ...,.... */
#方式1: SELECT d.department_id,d.department_name FROM employees e RIGHTJOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` ISNULL;
#方式2: SELECT department_id,department_name FROM departments d WHERENOTEXISTS ( SELECT* FROM employees e WHERE d.`department_id` = e.`department_id` );
#方式3(推荐):如果要创建的数据库已经存在,则创建不成功,但不会报错。 CREATE DATABASE IF NOTEXISTS mytest2 CHARACTERSET'utf8';
#如果要创建的数据库不存在,则创建成功 CREATE DATABASE IF NOTEXISTS mytest3 CHARACTERSET'utf8';
SHOW DATABASES;
#1.2 管理数据库
#查看当前连接中的数据库都有哪些 SHOW DATABASES;
#切换数据库 USE atguigudb;
#查看当前数据库中保存的数据表 SHOW TABLES;
#查看当前使用的数据库 SELECT DATABASE() FROM DUAL;
#查看指定数据库下保存的数据表 SHOW TABLES FROM mysql;
#1.3 修改数据库
#更改数据库字符集 SHOWCREATE DATABASE mytest2;
ALTER DATABASE mytest2 CHARACTERSET'utf8';
#1.4 删除数据库
#方式1:如果要删除的数据库存在,则删除成功。如果不存在,则报错 DROP DATABASE mytest1;
SHOW DATABASES;
#方式2:推荐。 如果要删除的数据库存在,则删除成功。如果不存在,则默默结束,不会报错。 DROP DATABASE IF EXISTS mytest1;
DROP DATABASE IF EXISTS mytest2;
#2. 如何创建数据表
USE atguigudb;
SHOWCREATE DATABASE atguigudb; #默认使用的是utf8
SHOW TABLES;
#方式1:”白手起家”的方式
CREATETABLE IF NOTEXISTS myemp1( #需要用户具备创建表的权限。 id INT, emp_name VARCHAR(15), #使用VARCHAR来定义字符串,必须在使用VARCHAR时指明其长度。 hire_date DATE ); #查看表结构 DESC myemp1; #查看创建表的语句结构 SHOWCREATETABLE myemp1; #如果创建表时没有指明使用的字符集,则默认使用表所在的数据库的字符集。 #查看表数据 SELECT*FROM myemp1;
#方式2:基于现有的表,同时导入数据
#基于查询语句创建的表 CREATETABLE myemp2 AS SELECT employee_id,last_name,salary FROM employees;
DESC myemp2; DESC employees;
SELECT* FROM myemp2;
#说明1:查询语句中字段的别名,可以作为新创建的表的字段的名称。 #说明2:此时的查询语句可以结构比较丰富,使用前面章节讲过的各种SELECT CREATETABLE myemp3 AS SELECT e.employee_id emp_id,e.last_name lname,d.department_name FROM employees e JOIN departments d ON e.department_id = d.department_id;
SELECT* FROM myemp3;
DESC myemp3;
#练习1:创建一个表employees_copy,实现对employees表的复制,包括表数据 CREATETABLE employees_copy AS SELECT* FROM employees;
SELECT*FROM employees_copy;
#练习2:创建一个表employees_blank,实现对employees表的复制,不包括表数据 CREATETABLE employees_blank AS SELECT* FROM employees #where department_id >10000; WHERE1=2; #山无陵,天地合,乃敢与君绝。
INSERTINTO emp1(id,NAME,salary,hire_date) #查询语句 SELECT employee_id,last_name,salary,hire_date # 查询的字段一定要与添加到的表的字段一一对应 FROM employees WHERE department_id IN (70,60);
#cartoon显示卡通,joke显示笑话 SELECT NAME "书名",note,CASE note WHEN'novel'THEN'小说' WHEN'law'THEN'法律' WHEN'medicine'THEN'医药' WHEN'cartoon'THEN'卡通' WHEN'joke'THEN'笑话' ELSE'其他' END "类型" FROM books;
17、查询书名、库存,其中num值超过30本的,显示滞销,大于0并低于10的,
#显示畅销,为0的显示需要无货 SELECT NAME AS "书名",num AS "库存", CASEWHEN num >30THEN'滞销' WHEN num >0AND num <10THEN'畅销' WHEN num =0THEN'无货' ELSE'正常' END "显示状态" FROM books;
18、统计每一种note的库存量,并合计总量
SELECT IFNULL(note,'合计库存总量') AS note,SUM(num) FROM books GROUPBY note WITHROLLUP;
19、统计每一种note的数量,并合计总量
SELECT IFNULL(note,'合计总量') AS note,COUNT(*) FROM books GROUPBY note WITHROLLUP;
20、统计库存量前三名的图书
SELECT* FROM books ORDERBY num DESC LIMIT 0,3;
21、找出最早出版的一本书
SELECT* FROM books ORDERBY pubdate ASC LIMIT 0,1;
22、找出novel中价格最高的一本书
SELECT* FROM books WHERE note ='novel' ORDERBY price DESC LIMIT 0,1;
23、找出书名中字数最多的一本书,不含空格
SELECT* FROM books ORDERBYCHAR_LENGTH(REPLACE(NAME,' ','')) DESC LIMIT 0,1;